Age-Related Deficits in the Processing of Fundamental Frequency Differences for the Intelligibility of Competing Voices
Article information
Abstract
A common complaint of older listeners is that they can hear speech, yet cannot understand it, especially when listening to speech in a background noise. When target and competing speech signals are concurrently presented, a difference in the fundamental frequency (ΔF0) between competing speech signals, which determines the pitch of voice, can be an important and commonly occurring cue to facilitate the separation of the target message from the interfering message, consequently improving intelligibility of the target message. To address the question of whether the older listeners have reduced ability to use ΔF0 and how the age-related deficits in the processing of ΔF0 are theoretically explained, this paper is divided into three parts. The first part of this article summarizes how the speech-communication difficulties that older listeners have are theoretically explained. In the second part, literatures on the perceptual benefits from ΔF0 and the age-related deficits on the use of ΔF0 are reviewed. As a final part, three theoretical models explaining the general processing of ΔF0 are compared to discuss which better explains the age-related deficits in the processing of ΔF0.
Introduction
Understanding a spoken message in the presence of background noise or competing speech is a common listening problem for many older adults. The recognition process in the presence of competing signals is naturally complicated since it includes the encoding of each input signal at the peripheral level, followed by processing of the central auditory and cognitive systems. When age-related internal changes occur in peripheral, central, and general cognitive functions, any one of these changes can be sufficient to affect the understanding of competing speech signals, but older adults often experience changes at multiple levels of processing. When the target and competing voices are presented together, young adults are able to use differences in the fundamental frequency (ΔF0) of competing speech signals in order to better identify the target message against the interfering message. However, this important cue may not be ideally processed for older listeners, revealed by numerous studies that reported the age-related disadvantage in the processing of ΔF0 for the intelligibility of competing signals. Thus, it is important to determine any negative impact of aging on the use of ΔF0 cues between two competing speech signals, and various theoretical models which describe possible reasons of the age-related deficits above. This article addresses three issues, 1) theoretical hypotheses about age-related deficits on general speech communication, 2) previous findings on the perceptual benefits of ΔF0 for competing speech signals and the age-related deficits on these benefits, and 3) theoretical models on the processing of ΔF0 in order to compare which better explains the age-related disadvantage in the processing of ΔF0.
Age-Related Deficits on Speech Communication
A working group of the Committee on Hearing and Bioacoustics and Biomechanics of the National Research Council reviewed the issues of the speech communication problems in older adults. As a possible explanation of age-related deficits on speech communication, the sensori-neural hearing loss and cochlear pathology of older listeners can result in difficulties for the peripheral encoding of input sounds, and the age-related decline in central-auditory and general cognitive functions can also adversely influence processing of deteriorated input signals.1) When the age-related peripheral deficit in hearing sensitivity, often referred to as presbycusis, is the sole deficit, the listener's understanding of the target message is primarily affected by the inaudibility of the target speech arising from the presence of cochlear pathology.2-6) Because this age-related hearing loss rarely results in total deafness, most of older adults with presbycusis can still hear speech, but often have difficulty understanding speech. Given the normal involvement of processing at peripheral, central-auditory, and cognitive levels in speech understanding, three hypotheses (i.e., auditory peripheral hypothesis, central-auditory hypothesis, and general cognitive hypothesis) have been used to explain the speech-understanding difficulties of the elderly adults with impaired hearing.1,7)
Age-related structural and functional changes in the auditory periphery have been assumed to directly affect the audibility and the processing of speech sounds in the peripheral hypothesis. The age-related peripheral hearing loss often starts in the high frequencies, with a progressive deterioration at high frequencies that is faster than at low frequencies. Due to the high-frequency hearing loss, some high-frequency, low-intensity speech sounds, usually consonantal sounds such as "t, f, s, th", can become inaudible even when a single talker speaks at typical conversational levels (60-65 dB SPL) in quiet conditions.8) Many previous studies have consistently found that older individuals' speech-understanding performance is well-explained by the audibility of speech, estimated from hearing thresholds, when a single talker speaks in quiet or in a steady-state background noise.3,7-11)
When a target speech signal is presented with a background noise that fluctuates like speech or with competing speech, individual differences in the speech-understanding performance of older individuals are not predicted by audibility alone. Rather, age-related deficits often emerge as primary or strong secondary predictors.11,12) The role of age-related deficits in central-auditory and general cognitive process has also been confirmed in several studies.2,11-16) Once the reduced speech audibility of the target message has been alleviated by clinical amplification or laboratory spectral shaping, other factors associated with central and cognitive deficits emerge, especially while listening to speech with competing speech in the background. When the target and interfering messages are presented concurrently, spectral and temporal features of both competing speech signals are encoded and contrasted in order to segregate the target from the competing source. For the procedure of identification for multiple speech streams, listeners need to divide their attention to monitor multiple conversations, and then selectively attend to one speech stream while inhibiting the competing information.15) The age deficits in cognitive processing also contribute to speech-understanding difficulties in a multitalker conversation, possibly influenced by declined attentional capacity and inefficient allocation of attentional resources.
As described above, all the age-related vascular, metabolic, or other systemic factors can cause detrimental changes to peripheral, central-auditory, or cognitive processes, yet various acoustic external factors such as fundamental frequency differences between competing voices can also impact the auditory segregation of collocated competing signals.
Benefits from F0 Differences for Intelligibility of Competing Speech
The fundamental frequency (F0) is critical to speech perception especially in noise since ΔF0 provides an important and robust cue to segregate multiple speech streams. The fundamental frequency means the frequency at which the vocal folds vibrate for making voiced speech sounds, and the vibration generates a periodic fluctuation of air pressure. F0 is calculated based on the number of vibrations per second and this is generally expressed in units of Hertz (Hz). F0 is inversely proportional to the vibrating mass and directly proportional to the tension (stiffness) of the vocal folds. Depending on the features of mass or tension, a slow or fast vibration of vocal folds yields a low or high F0 value, consequently eliciting a low- or high-pitched sound. For example, the F0 value of men is typically an octave lower than that of women due to the longer and heavier vocal folds, eliciting a low-pitch sensation (e.g., F0 of 132 Hz for men and 224 Hz for women).17) F0 can be raised when a speaker increases tension to the vocal folds. The F0 value conveys not only the acoustic cues to vowel identity, intonation, and talker's gender, but also the cues on the speakers' age and even emotional state.16)
When listeners simultaneously hear two speech signals with different F0s, it is easier to separate one from the other sound source. There is ample evidence that F0 separation remarkably improves performance for concurrent speech sounds overlapping in frequency and time, when the test materials were competing vowels,18-22) competing non-sense syllables,23) and competing sentences.16,24-26)
A doubling of sound frequency is known as an octave. The octave interval is divided into twelve semitones (STs), which results in one ST corresponding to the 12th root of 2 (i.e.,1 ST=1.0595). When concurrent vowels have been studied, often using a method referred to as the "double-vowel paradigm", a small difference in F0 of less than 1 ST dramatically enhanced identification accuracy or segregation perception. With ΔF0 greater than 2 ST, performance often reached an asymptote for normal-hearing (NH) listeners27-29) or both NH and hearing-impaired (HI) listeners.30)
In contrast to the asymptote in the double-vowel paradigm, the young adults' identification of competing sentences received a gradual and progressive benefit from F0 shifts beyond 2 ST, regardless of whether the natural variation of F0 over time was preserved or artificially removed.24,25,31,32) Besides the robust benefit from F0 separation in young normal hearers, ΔF0 benefit has also been found in HI listeners with cochlear pathology and in older adults.18,19,22,30,33-35) For example, the ability of 8 NH (age range: 21-30 yrs) and 9 HI (age range: 36-70 yrs) listeners to utilize ΔF0s was compared in a monotonic double-vowel paradigm.18) In this experimental design, each vowel was made sufficiently audible to the HI group by a presentation level of at least 90 dB SPL. Overall, NH participants outperformed the HI group in vowel identification, yet the amount of benefit from a ΔF0 of 2 ST was similar to each group (about 17-18 percentage points of improvement). The ΔF0s greater than 2 ST did not progressively enhance the vowel identification of either group. Results of masked vowel thresholds showed that both NH and HI groups could identify the weaker-intensity target vowel against the more intense masker vowel, regardless of F0 separation between vowel pairs. Taken together, the poorer identification and greater masking in the HI group (compared to the NH group) led the authors to speculate that both would lead to less efficient use of ΔF0 cues by the HI.
As a series of studies,33) the double vowels were spectrally adjusted by introducing 25 dB of gain at frequencies above 1000 Hz and additionally tested six HI listeners (1 HI: 38 yrs, 5 HI: 53-69 yrs) who participated in the earlier study.18) Despite high-frequency amplification ensuring the audibility of frequencies corresponding to the second and higher formants of vowels, the authors failed to observe a significant improvement in the overall identification performance of the HI group compared to that achieved without amplification. This suggests that the suprathreshold deficits in spectro-temporal processing, rather than speech audibility alone, contribute to the double-vowel performance of HI listeners.
A follow-up study19) measured the ability to detect the presence of two different vowels and identify target words in young NH listeners and HI individuals of various ages (age range: 19-76 yrs). In this double-vowel paradigm, two experiments were conducted where ΔF0, presentation mode, and target-to-masker ratio (TMR) at which listeners could just identify target vowels in the presence of a masking vowel were varied. Results of the first experiment showed that the HI listeners were less accurate at identifying the target vowels than the NH group across five TMRs, although a strong benefit from ΔF0 of 2 ST was observed in both groups. In the second experiment, both NH and HI groups were superior at using ΔF0 cues in the dichotic condition compared to the monaural condition, with a greater dichotic benefit in the HI group than in the NH group. Given the reduced overall ability of HI group in vowel identification of two experiments, the authors conjectured that the increased susceptibility to peripheral masking from broadened auditory filters would degrade the internal representations of competing vowels and consequently yield poorer double-vowel perception for the HI group.
In another study,30) competing vowels were separated by ΔF0 values from 0 to 9 ST and also the vowels' harmonic structures were manipulated in order to explore whether the use of ΔF0 depends on the disruption of harmonic structures in the low- or high-frequency regions. When the harmonic structures of five synthesized vowels were not disrupted, a ΔF0 of 0.5 ST improved the vowel-identification performance of the NH group by 33 percentage points and the same F0 separation benefited the HI group by 29 percentage points. Neither group received additional benefit from ΔF0 values beyond 1 ST, which was consistent with the asymptote in other double-vowel studies. When the harmonic structures of double vowels were manipulated, the NH and HI groups were both effective at utilizing F0 cues in the lower-formant (F1) frequency region. However, the HI listeners inefficiently derived F0 information from higher-order harmonics (F2-F5). Their findings supported a lack of negative effects of hearing loss when making use of the F0 cues, at least, in the low-frequency region, and thus suggested an association between the degraded use of ΔF0 in the HI listeners and their reduced frequency selectivity at high frequencies.
The previous studies described above18,19,30,33) only focused on the use of ΔF0 in a double-vowel paradigm. Very few studies measured identification of both concurrent vowels and sentences. For example, the performance of middle-aged and older listeners with NH (age range: 49-74 yrs) or with hearing impairment (age range: 59-77 yrs) was measured on three tasks.35) The three tasks tested were F0 discrimination of a single vowel and the identification of competing vowels and sentences. The results for the difference limen of F0 (F0 DL) across five steady-state synthetic vowels revealed a greater sensitivity of NH listeners to F0 difference (0.5-2 Hz for F0 DL) compared to the HI listeners (1-4 Hz for F0 DL). When the subjects identified concurrent vowels, the F0 shift from 0 to 4 ST provided the NH group with a perceptual benefit of 20 percentage points while the same ΔF0 increased the mean identification accuracy of the HI group by only 8 percentage points. The authors reported not only the slightly less ΔF0 benefit in the HI group compared to the NH group on the double vowels and double sentences, but also larger individual differences in performance of HI listeners. Interestingly, a different factors appeared to be related to the large intersubject variability of HI listeners for three-task performances.35) Hearing sensitivity of the HI individuals at 2000 Hz was predictive of their sensitivity to the F0 differences on the discrimination task. In contrast, chronological age best accounted for the amount of ΔF0 benefit in the competing vowel or sentence paradigms, indicating an association between age-related internal changes among the middle-aged and elderly participants and the higher-level processing required for the identification of competing speech signals. A weak link between double-vowel and double-sentence identification was also found, and this emphasized a possibility of overgeneralization of results from competing-vowel studies to competing-sentence performance, at least for the middle-aged and older listeners.
As noted, several previous studies18,19,30) agreed on the deleterious effect of cochlear hearing loss on performance in a double-vowel paradigm. Those studies above, however, included a relatively small sample size. In addition, there were often substantial age differences between the NH and HI groups. Recently, the age-related deficits become more focused. For example, the abilities between younger adults with normal hearing (YNH) and eldely listeners with normal hearing (ENH) compared to demonstrate the age-related deficits in the use of F0 separation in a double-vowel paradigm.22) In the double-vowel paradigm, F0 DL measures using a synthesized vowel and vowel-identification performance using F0-separated double vowels were examined. When the F0 of the vowel /a/ was increased in steps of 0.1 Hz under monaural presentation, the ENH listeners were three times less sensitive to ΔF0 compared to the YNH. Here, individual differences in F0 DL were significantly correlated with age among the older adults. When the concurrent vowels were identified, mean identification accuracy of both listener groups improved markedly as F0 increased from 0 to 0.5 ST in F0, yet not beyond a 0.5 ST shift. Moreover, the ENH group was, on average, less accurate than the YNH group in identifying both vowels, yet the vowel identification of three ENH individuals was comparable to the mean identification accuracy of the YNH group. Analyses of error responses revealed that incorrect responses of both the YNH and the ENH groups occurred more from the misidentification of one vowel than from both vowels, suggesting a presence of vowel dominance. Based on the results and the association between synchrony coding and benefit from ΔF0 argued by de Cheveigné,36) the authors concluded that an age-related loss of neural synchrony increasing temporal jitter would evoke a declined periodicity coding and consequently a degraded benefit from ΔF0 for concurrent speech signals.
A recent study16) examined the negative effects of both hearing loss and age-related declines on the use of ΔF0 by comparing four listener groups differing in hearing status and age. Results showed that F0 cues were beneficial to both cue-word detection and color-number identification performance. Elderly adults with impaired hearing had the greatest difficulty with the identification task despite the application of spectral shaping to restore the audibility of the speech stimuli. Also the authors concluded that the reduced audibility or aging alone is not the cause for the poor performance of the elderly HI listeners, indicating a combined contribution of hearing loss and aging on the reduced ΔF0 benefit.
As discussed above, age-related declines in the use of ΔF0 appeared to be clear in numerous studies. Then, how those deficits can be resolved? Can any hearing assistive devices help old people better access to ΔF0 cues? Recently, in order to address whether electro-acoustic and cochlear-implant hearing can enhance processing of ΔF0, both young and older listeners' use of F0 cues was compared in simulations of electro-acoustic and cochlear-implant hearing.37) Although the electric and acoustic stimulation (EAS) is known to allow the listeners to combine residual low-frequency hearing with electrical hearing, expecting a greater benefit from ΔF0s, some studies reported that old listeners may not benefit from EAS devices as much as young listeners. Thus, researchers37) focused on the ability of aged listeners in the processing of F0 cues using EAS and cochlear-implant hearing simulations. The age-related deficits in the perception of vowel multiplicity were found in terms of amount of ΔF0 benefit as well as overall identification. However, EAS simulation provided a large inter-subject variability in ΔF0 benefit of older individuals, consequently requiring more research on the effectiveness of EAS stimulus to the old individuals in using F0 cues and other various acoustic cues.
Theoretical Models on the Processing of F0 Differences
To understand the mechanism underlying the age-related degradation in the use of ΔF0 or periodicity coding, it is critical to review the different aspects of three models, spectral, spectro-temporal, and temporal models, that can account for the ΔF0 benefit observed for concurrent speech signals. In the spectral model, based on a place theory, auditory peripheral filtering is used to allocate frequency components corresponding to each competing vowel. According to the place theory of pitch, different pure tones produce maximal activity at different places with maximal activity near the base of the cochlea for high frequencies and near the apical part in the cochlea for low frequencies. These different spatial patterns of mechanical activity along the basilar membrane lead to activity in different auditory nerve fibers distributed along the length of the cochlea, producing the tonotopic responses of the auditory nerve.
Fig. 1 displays schematic magnitude spectra of mixtures of two different vowels, /i/, /a/, and mixed vowel of /i/ and /a/. As reported,38) the spectral envelope of the mixed vowels with different F0s shows peaks of each harmonic series at different frequencies corresponding to the first-formant (F1) frequency of each vowel, allowing a better resolution of individual harmonic structures. In contrast, the peaks in the spectral envelope of the mixed vowels with the same F0 are not separable as depicted by filled circles in Fig. 1, suggesting that information on the individual harmonic series of each vowel would be poorly resolved for the competing vowels with the same F0. That is, in the spectral model based on the peripheral filtering, the degree of spectral resolution of two competing vowels was assumed to directly affect the identification accuracy of competing vowels, or the perceptual benefit of ΔF0 in a double-vowel paradigm.
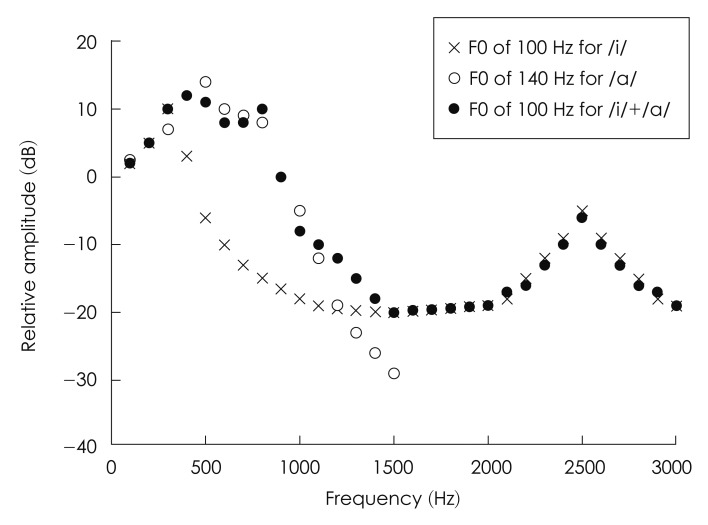
Schematic magnitude spectrum of mixtures of two different vowels, /i/ and /a/, with different F0s of 100 Hz and 140 Hz and with the same F0 of 100 Hz.
In the spectro-temporal model, the information of each vowel is analyzed in a series of auditory peripheral channels as in the spectral model. Yet, a subset of auditory channels responds to the period of one vowel and to the period of the other vowel. In this way, the periodicity corresponding to each vowel can be determined based on the spectro-temporal analysis over time even when the double vowels share the same auditory channel. When waveform interaction or beating is the basis of ΔF0 benefit in the spectro-temporal model,21,28,39) a remarkable ΔF0 benefit is possible even at small F0 separations between double vowels as long as the periodicity of the waveforms or the harmonicity of the speech signals is decoded.40) When there is a small ΔF0 between two vowels, the F0 or corresponding harmonics of each vowel can be closely located in terms of frequency and possibly excite the same region of the basilar membrane. Those two closely-spaced spectral or harmonic components might generate beating as a product of waveform interactions. For example, the Fig. 2A shows that a mixture of 125-Hz and 128-Hz pure tones produces rising and falling amplitude patterns or spectral envelopes with a repetition period of 3 Hz, which is a relatively slow modulation. Whereas, a mixture of 125-Hz and 200-Hz pure-tone (Fig. 2B) or of 125-Hz and 1000-Hz pure-tone (Fig. 2C) does not generate the same cyclical changes in envelope. When the temporal-envelope fluctuation of 3 Hz is added to the dynamic fluctuation of two competing sounds, this might allow the listeners to glimpse the target signal against the masker one. Better identification of longer-duration vowel pairs relative to shorter vowel pairs20,41,42) may be evidence of the spectro-temporal analyses since a longer duration might allow better encoding of a full modulation cycle in beating.

Relative amplitude spectrum of a mixture of 125-Hz pure-tone and 128-Hz pure-tone (A), of 125-Hz and 200-Hz pure-tone (B), and of 125-Hz and 1000-Hz pure-tone (C).
As spectro-temporal model, an array of autocorrelation functions or autocorrelated temporal patterns between signals was also used to explain ΔF0 benefit between concurrent vowels.43) In this spectro-temporal model based on autocorrelation segregation, autocorrelation functions of individual peripheral channel outputs are summed across channels. In a double-vowel paradigm, the largest peak within a summary of distributed autocorrelation function is considered a dominant periodicity, and all the channels with the dominant periodicity are selected to segregate a target vowel from a competing vowel. In other words, the auditory channels responding to the period of the dominant vowel are selected and partitioned from other channels, producing a strong ΔF0 benefit in vowel identification. Since the autocorrelation function determines the dominant periodicity or temporal pattern over the others, the requirement in this model is that each of the individual peripheral channels should be active for the different periodicities of each competing vowel, and the masker vowel should not dominate all the auditory channels.
Overall, the spectro-temporal models based on time-domain periodicity have been better than the spectral model in explaining the significant role of a very small F0 shift in the double-vowel paradigm, especially when the level of the target vowel is at or above that of the masker vowel. However, both the spectral model and the spectro-temporal model fail to explain how the F0 separation becomes beneficial to vowel identification even when the level of the target vowel is weaker, by 10 or 20 dB, than that of the interfering vowel,19,36,44) presumably making all the auditory channels dominated by the more intense vowel and the individual harmonics of the target vowel unresolved.
A temporal model based on a neural cancellation mechanism was proposed to explain the salient ΔF0 benefit at negative TMRs more effectively.36) The temporal model based on the neural cancellation filter employs the temporal discharge pattern of auditory nerve fibers occurring within a channel, rather than requiring harmonic resolution across channels. Fig. 3 demonstrates how the neural cancellation filter works by displaying a discharge distribution of an auditory never fiber in response to a 100-Hz pure-tone pulse.36) The auditory-nerve fiber response to a single vowel with F0 of 100 Hz is represented as a simple half-wave rectified sine wave of 100 Hz in Fig. 3A, and this serves as the input to the neural cancellation filter to the vowel. The neural cancellation filter calculates a delay that corresponds to the periodicity within input spikes and cancels the input spikes corresponding to the delay pattern, seen as the output of the cancellation filter in Fig. 3B. Fig. 3C is another input consisting of a half-wave rectified sum of two sine waves, 100 Hz (target) and 80 Hz (competing), corresponding to a mixture of 100-Hz target vowel and 80-Hz masker vowel with a 10-dB greater intensity. With competing vowels with different F0 values, the neural cancellation filter calculates a delay according to different periodicity of each vowel and is tuned to cancel the period of the masker vowel, discarding information about the periodicity of the masker vowel, as displayed in Fig. 3D.
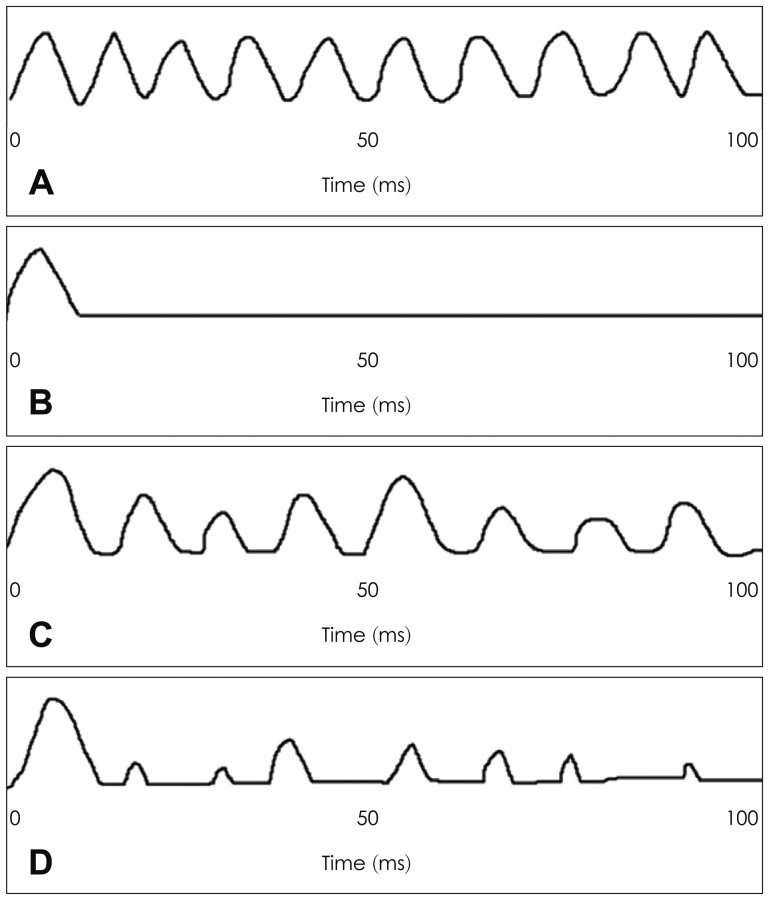
A: Neural cancellation filter input of 100-Hz half-wave rectified sinewave for a single vowel with F0 of 100 Hz. B: Neural cancellation filter output of A. C: Neural cancellation filter input of half-wave rectified sum of two sines, 80-Hz and 100-Hz for double vowels (differing in amplitude by 10 dB), and D: neural cancellation filter output of C.
The temporal model is based on the periodicity calculation, and this thus supposes that auditory system can derive pitch information from the period of discharges of auditory nerve fibers that do not resolve individual harmonics of the speech signal, even though the target vowel is presented with the more intense masker vowel. In other words, the temporal model selects the auditory channels based on the neural cancellation filters, not based on the outputs of auditory peripheral channels. This also appears consistent with some behavioral findings of a strong ΔF0 benefit at unfavorable TMRs.19,44) Using the guinea pig, the distribution of neural synchrony was examined across the population of auditory nerve fibers.45,46) By counting the spikes in bins synchronized with the double vowels, a histogram was constructed determining interspike interval distributions of the auditory nerve to the mixed vowel. The data were well fit via temporal analysis, compared to fits by spectral or spectro-temporal analyses. Other animal studies, based on a wide variety of measurements, have observed an age-related reduction in the synchrony of auditory nerve fiber responses.47-51)
As noted above, among the three types of model that have been developed, the temporal model provides the most favorable explanation for ΔF0 benefit at low TMR values and for the age-related reduction in the ΔF0 benefit for the vowel identification. If the older listeners have reduced neural activity or a loss of neural synchrony, this would result in a decline in periodicity coding and an inefficient neural cancellation of competing speech signals. However, this does not necessarily mean that the deleterious effect of cochlear hearing loss would be unrelated to the outputs of the neural cancellation operation. Although a broadening of auditory filters due to cochlear pathology would not directly damage the process of neural cancellation operations per se, the reduced input information due to the reduced audibility would, at least partially, degrade the input into the neural cancellation filter, possibly limiting the effectiveness of the neural cancellation filter.
Conclusion
The primary objective of this study was to provide information on the age-related declines in the use of ΔF0s between competing voices and the controversial theoretical explanations on this issue. As reviewed, aging adversely affected the identification of the target speech, either vowel or sentence, against interfering competing speech. As a possible explanation, aging can negatively influence neural encoding of the temporal properties in competing sounds, consequently resulting in a declined periodicity coding and an inefficient neural cancellation of competing speech signals. This was better supported by temporal model based on the periodicity calculation compared to other theoretical models. In order to improve the ability of older adults to utilize ΔF0s between competing voices, future studies are needed to investigate innovative technical development of the hearing assistive devices focusing on better access to the F0 segregation cues and also deriving greater ΔF0 benefits to the older listeners.