Introduction
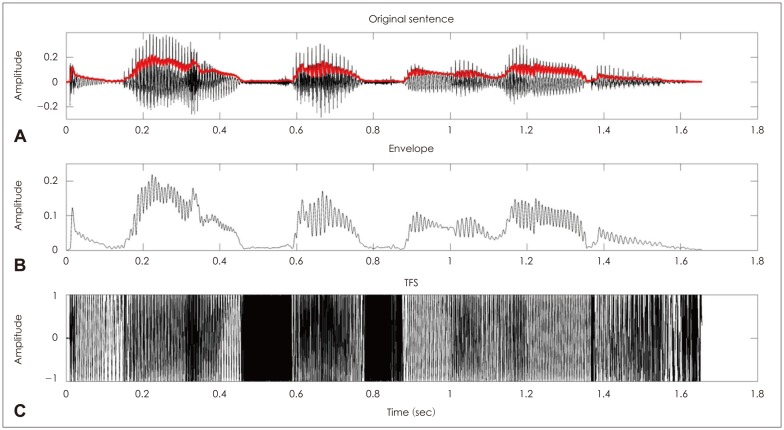
Multiple acoustic cues are usually used to interpret and understand speech in the human auditory system. These acoustic cues are largely classified on the basis of their temporal and spectral properties. The temporal properties can be further classified into the magnitude of the Hilbert transform on the speech signals and its phase information. The basic representation of speech stimuli at all levels of the auditory system is tonotopic, meaning that different frequencies in the stimulus are analyzed separately. Thus, spectral information of speech is processed as a result of cochlear filtering, which is a kind of series of bandpass-filtered signals. Each filtered signal corresponds to one specific place on the basilar membrane. The time signal at a specific position on the basilar membrane can be decomposed by using the Hilbert transform into two forms of temporal information, temporal envelope (ENV) and temporal fine structure (TFS)(Fig. 1). The ENV is characterized by the slow variation in the amplitude of the speech signal over time, while TFS is the rapid oscillations with rate close to the center frequency of the band.1) Both ENV and TFS information are represented in the timing of neural discharges. It is commonly believed that ENV cues are represented in the auditory system as fluctuations in the short-term rate of firing in auditory neurons, while TFS is represented by the synchronization of nerve spikes to a specific phase of the carrier (phase locking).2) Although the upper limit of phase locking in humans is unknown yet, phase locking begins to weaken for high frequencies above 4-5 kHz in most mammals.
It has been of considerable interest to understand the relative contribution of these acoustic cues for speech perception. A number of studies have investigated the roles the cues to understand which are particularly important for speech perception in quiet and in complex backgrounds.3,4,5,6,7,8,9) This paper will especially describe the role of TFS information in speech perception and its clinical applications.
Techniques to Evaluate the Effect of Acoustic TFS on Speech Perception
To investigate the role of TFS in speech perception, a variety of techniques have been developed and applied. The main concepts of these techniques are splitting sound into multiple frequency bands and processing the signal in each band to preserve only ENV or TFS cues, or varying TFS information in each band.
Smith, et al.10) first developed "speech chimeras", which have the ENV of one sound and the TFS of another, to investigate the relative perceptual importance of ENV and TFS in different acoustic situations. A bank of band-pass filters is used to split each sound, and the output of each filter is factored into its ENV and TFS using the Hilbert transform. The ENV of each filter output from the first sound is then multiplied by the TFS of the corresponding filter output from the second sound, and these are summed over all frequency bands to produce "chimeras". That is, the chimeras are made up of the ENV of the first sound and the TFS of the second sound in each band. Using speech chimeras, the authors revealed that TFS is important for pitch perception and sound localization.
Other way to study the role of TFS is to remove ENV cues in the speech as far as possible while TFS cues are preserved.11) Thus, "TFS-speech", which contains TFS information only, have been developed and used for investigating the role of TFS on speech perception. The Hilbert transform was used to decompose the signal in each frequency band into its ENV and TFS components. Then, the ENV component was removed. As a result, each band signal becomes like an frequency modulations (FM) sinusoidal carrier, with a constant amplitude. The TFS in each band was multiplied by a constant equal to the root-mean square amplitude of the original band signals. The "power-weighted" TFS signals were then combined over all frequency bands.
Although this precise processing preserves TFS information to some extent, the TFS information can be distorted from the original TFS in the unprocessed speech. In addition, Ghitza12) showed the recovered ENV cues from TFS-speech, which are reconstructed at the outputs of the auditory filters. This reconstructed ENV cues may influence the intelligibility of TFS-speech. After that, Lorenzi, et al.9) showed evidence indicating that only minimal influence was observed from reconstructed ENV cues when the bandwidth of the analysis filters was narrow (less than 4 equivalent rectangular bandwidth).
A series of recent studies by Hopkins, et al.4,5,13) used a different approach to evaluate the contribution of TFS to speech perception in background noise. They measured speech reception thresholds in noise as a function of the number of channels containing TFS information. Signals were left unprocessed for channels up to a certain frequency limit (i.e. both ENV and TFS information are preserved) and were vocoded for higher frequency channels (i.e. only ENV information is preserved). As the cut-off channel increased, the amount of TFS information available also increased.
The Role of TFS on Pitch Perception
Pitch is important for speech and music perception as well as segregating sounds that arrive from different sources. If fundamental frequency (F0) and its perceptual correlate-pitch-of simultaneous sounds are same, the sounds are more likely to be heard as a single object. Thus, patients with cochlear hearing loss or cochlear implant (CI) users who have poorer pitch perception ability may have some difficulties in understanding or segregating speech in complex everyday acoustic environments.14) Previous studies over many years suggests that TFS plays a role in the pitch perception for both pure and complex tones.15) Especially, Smith, et al.10) reported a significant role of TFS information on pitch perception of complex harmonic sounds by using chimaeras. They synthesized chimaeras based on two different melodies, one in the ENV and the other in the TFS. Up to 23 frequency bands, listeners always heard the melody based on the TFS, while the ENV-based melody was more often heard with 48 and 64 frequency bands. This result suggests that melody reception depends primarily on TFS information in broad frequency bands. In contrast, when using speech-speech and speech-noise chimaeras, the crossover point, where the envelope begins to dominate over the fine structure, occurs for a much lower number of frequency bands. Thus, in contrast to pitch perception, speech recognition mainly depends on ENV information in broad frequency bands.
The Role of TFS on Speech Recognition in Noise
ENV cues are sufficient to give good speech intelligibility in quiet, but they are not enough in the presence of background noise. That means ENV cues alone are not sufficient to perceptually segregate mixtures of sounds. A number of previous studies have suggested that TFS is required for speech perception in noise, particularly fluctuating noise, such as a competing talker.4,9)
It is usually easier to detect a speech in modulated than in steady noise condition, especially when the frequency between the signal and noise is different. This effect has usually been ascribed to the ability to "dip listening" of the fluctuating background sound. Moore and Glasberg16) have demonstrated that TFS provides a cue that allows effective dip listening when the masker and signal frequencies fall in the range where phase locking is relatively precise. However, for the highest masker center frequency where phase locking is weak or absent, the difference of thresholds in the modulating masker and in the steady masker (masking release) became smaller, at about 10 dB. This dramatic decrease in masking release for the masker centered at high frequencies is consistent with the idea that the mechanism that decodes TFS information is less effective when there are rapid changes in TFS. The other study regarding masking experiments has also been interpreted as indicating a role of TFS in dip listening.17) To assess the role of TFS information in dip listening, Hopkins, et al.4,13) used a different approach to assess the use of TFS in speech perception. They measured speech recognition thresholds in steady and modulated noise for signals that were filtered into 32 bands and tone vocoded above a variable cut-off band. Filtered sound below the cut-off band contained intact TFS and ENV information, while the other bands were noise or tone vocoded, so only ENV information was conveyed in those bands above the cut-off band. As expected, normal-hearing listeners showed an improvement in speech perception (by about 15 dB in speech reception thresholds) in noise as more TFS information was added. In addition, the improvement in speech reception was larger for the modulated than steady noise condition. This result is in consistent with the concept TFS information plays a significant role in the ability to identify speech in a fluctuating background.
Reduced Ability to Use TFS in Hearing-Impaired Listeners
Hopkins, et al.4) directly assessed the ability to use TFS information in hearing-impaired listeners. Speech reception thresholds in a competing talker background were assessed using signals with variable amounts of TFS information in normal-hearing and hearing-impaired subjects. Hearing-impaired group showed less benefit from the additional TFS information than normal-hearing group. In addition, there are a lot of individual variability regarding the benefit in hearing-impaired listeners. This reduced ability to use TFS information in hearing-impaired group may be partially responsible for decreased ability of listening in a fluctuating background than normal-hearing group.
Another experiment by Hopkins and Moore18) measured ability to use TFS by discriminating a harmonic complex tone from a tone in which all components were shifted upwards by the same amount in Hz. Non-shaped stimuli, containing five equal-amplitude component, or shaped stimuli, contained many component and passed through a fixed bandpass filter to reduce excitation pattern changes, were used in the experiment. The performance for the shaped stimuli in hearing-impaired group was much poorer than that in normal-hearing group, suggesting that they could not use the TFS information effectively. However, the performance for the non-shaped stimuli in hearing-impaired group was significantly improved, suggesting that the hearing-impaired listeners may benefit from spectral cues. In contrast to hearing-impaired listeners, normal-hearing subjects are able to use TFS information to discriminate inharmonic and frequency-shifted complexes with components that are unresolved.
Some previous studies regarding speech perception have also investigated the effect of cochlear hearing loss in understanding speech with emphasis on TFS information. Lorenzi, et al.9) designed an experiment using unprocessed, ENV-speech, and TFS-speech in quiet for three groups: young with normal hearing, young with moderate hearing loss, and elderly with moderate hearing loss. Normal hearing listeners can understand all three types of speech with more than 90% correct rates. Performance for unprocessed and ENV-speech in both young and elderly listeners with hearing loss are almost similar to normal hearing group. However both groups with hearing loss performed very poorly with TFS-speech, suggesting that cochlear hearing loss negatively affect the ability to use TFS. Hopkins, et al.4) also reported similar results that the hearing-impaired group performed more poorly than the normal-hearing group in all test conditions, and the difference between the two groups becomes greater with addition of TFS information.
Moore1) proposed several possible reasons regarding the reduced ability to use TFS information in hearing-impaired listeners. First, cochlear hearing loss can cause reduced synchrony capture (reduced precision of phase locking), possibly as a result of diminished two-tone suppression. Second, the relative phase of response at different points along the basilar membrane can be changed in hearing-impaired listeners, which could influence mechanisms for decoding TFS. Third, due to broadened auditory filters, more complex and rapidly-varying TFS are generated, which might be difficult for central mechanisms to decode the TFS information. Fourth, a shift in frequency-place mapping caused by hearing loss may disrupt the decoding process of TFS information. Fifth, there may be central changes following hearing loss, such as loss of inhibition, and this might make it more difficult to decode the TFS information.
Reconstructed ENV from TFS
There have been debates about the real role of TFS information in speech perception using a vocoder study. Some researchers have argued that the TFS role for speech perception have been somewhat overestimated because the ENV cues can be reconstructed from TFS cues in the human auditory filters. Modelling work by Ghitza12) has demonstrated that the degraded speech-envelope cues may be recovered at the output of auditory filters because the signal's envelope and instantaneous frequency information are related. Thus, it is still unclear how TFS information contributes to speech intelligibility. Besides phase-locking in auditory-nerve fibers, these recovered ENV cues may be responsible for the speech intelligibility in a real world.19)
Gilbert and Lorenzi20) assessed the contribution of recovered ENV cues to speech perception as a function of the analysis bandwidth in normal hearing listeners. In this study, ENV cues recovered at the output of auditory filters can be used by listeners to identify consonants especially when the bandwidth is broad. However, when the analysis bandwidth was narrower than four times the bandwidth of a normal auditory filter, the recovered ENV cues did not play a significant role in speech perception. For patients with mild to moderate hearing loss, cochlear damage reduces the ability to use the TFS cues of speech, and this is partially due to poor reconstruction of ENV from TFS.21)
Won, et al.22) evaluated the mechanism of recovered ENV in CI users. Stimuli containing only TFS information were created using 1, 2, 4, and 8-band FM-vocoders. A consistent improvement was observed as the band number decreased from 8 to 1 (as more ENV were reocovered). This result indicates that CI sound processor can generates recovered ENV cues from broadband TFS, and CI users can use the recovered ENV cues to understand speech.
Cochlear Implant and Temporal Fine Structure
Several sound processing strategies have been developed over time for multi-channel implants. One of the most frequently used strategy in implant signal processing is the continuous interleaved sampling (CIS). In the CIS, sound is passed through a bank of bandpass filters, and the ENV of each filter output is obtained via rectification and lowpass filtering. However, during the lowpass filtering of the envelope, TFS cues are largely discarded, and this is one of the important limitations of sound processing strategies in CI today. That is, current CI systems convey mainly ENV information in different frequency bands. Furthermore, ENV cues are known to be more susceptible to noise degradations than intact speech. Over decades, speech recognition of CI users has improved dramatically. However, the performance of speech perception by CI users is still not comparable to that of normal-hearing listeners, and this difference in performance is especially noticeable for speech perception in noise as well as music perception. Therefore, the lack of TFS cues in conventional CI encoding strategies reduces temporal pitch cues and may be responsible for the generally poor performance of understanding speech in noise and music in CI users.
This hypothesis has given motivation to develop new implant signal processing strategies to contain TFS cues in addition to ENV cues.23,24,25,26) However, most CI users have the reduced sensitivity to temporal modulation in electric hearing. Changes in the repetition rate of the electric waveform above approximately 300 Hz cannot be processed in most CI users, while TFS typically oscillates at a much higher rate.27) To overcome this limitation in delivering TFS information to CI users, several approaches have been attempted. The HiRes strategy uses a relatively high envelope cutoff frequency and pulse rate to improve TFS information. Nie, et al.,24) proposed a new strategy which encodes both amplitude and FM. In the strategy, by removing the center frequency from the subband signals and additionally limiting the FM's range and rate, it transforms the rapidly-varying TFS into a slowly varying FM signal which was applied to the carrier in each band. They found that adding this FM signal improved performance by as much as 71% for sentence recognition in babble noise. Analog strategies also can be used for TFS transmission, but it increases electrode interaction, which ultimately decrease CI users' perceptual abilities.
Recently, to encode TFS information for CI users, a harmonic-single-sideband-encoder (HSSE) strategy was developed.25,26) The main difference of HSSE from other strategies is that the HSSE use incoherent approaches to extract temporal cues, e.g. the Hilbert envelope or half/full wave rectification followed by a low-pass filter. It explicitly tracks the harmonics of a single musical source and transforms them into modulators conveying both amplitude and TFS cues to electrodes. Using an auditory nerve model, the neural spike patterns evoked by HSSE and CIS for one melody stimulus were simulated, and it was revealed that HSSE can convey more temporal pitch cues than CIS. In addition, timbre recognition as well as melody recognition were significantly improved with HSSE.26) The results suggest that adding TFS cues using a specific processing strategy in CI users can enhance music perception with CIs.
Hearing Aid and Temporal Fine Structure
The healthy cochlea responds to sound in a way that is highly nonlinear and compressive. That means more gain applied at low sound levels than at high ones due to outer hair cell function. However, if outer hair cells are damaged, it can result in a more linear basilar membrane response. Consequently, patients with hearing loss (usually with some degree of outer hair cell damage) typically have problems like loudness recruitment and a reduced dynamic range.28) Most current hearing aids use this non-linear compression for patients with cochlear hearing loss. That is, the gain applied to a signal is inversely related with the signal input level, so intense sounds are less amplified than weak sounds. This compression schemes used in hearing aids are typically categorized as fast or slow acting, depending on the values of attack time and release time. Fast compression and slow compression have their own strengths and limitations. Overall, previous studies suggested that slow compression was better than fast compression based on measures of listening comfort, whereas fast compression was better than slow compression based on measures of speech intelligibility.29) However, there are large individual differences for overall outcome following use of hearing aids.
Hopkins, et al.4) reported high individual variability to use TFS information among hearing-impaired listeners. Moore30) suggested that an individual's sensitivity to TFS cue may affect which compression speed gives most benefit. Hearing aid users with good TFS sensitivity may benefit more from fast than from slow compression, because TFS information may be important for listening in the dips of a fluctuating background and fast compression increases the audibility of signals in the dips. This hypothesis was tested in normal-hearing listeners using vocoded signals. In the experiments, however, speech intelligibility was significantly better for fast compression than slow compression regardless of conditions. That means, the availability of original TFS or detailed spectral information does not affect the optimal compression speed.31) To confirm this result, the same experiments should be extended to patients with a real cochlear hearing loss.
Methods for Determining Sensitivity to TFS in Clinics
Recent evidence suggests that cochlear hearing loss adversely affects the ability to use TFS information in a variety of conditions, such as lateralization of sounds, pitch perception, and speech perception.14,18,32) Thus, clinical needs for accurately assessing ability to use TFS cue have been increased. Moore and Sek33) developed a simple and quick test for assessing sensitivity to TFS that can be used in clinical setting. The test is designed to discriminating a harmonic complex tone (H), with a fundamental frequency F0, from a similar tone in which all harmonics were shifted up by the same amount in hertz, which becomes an inharmonic tone (I). For example, tone H may contain components at 1600, 1800, 2000, 2200, 2400 Hz for an F0 of 200 Hz, while tone I may contain components at 1620, 1820, 2020, 2220, 2420 Hz. The starting phases of the components are chosen randomly for each stimulus. Both tones have an envelope repetition rate equal to F0, but the tones differ in their TFS. To reduce spectral cues, all tones are passed through a fixed bandpass filter, and the default value of the center frequency is 11F0. A background noise is used to mask combination tones. During the test, the amount of shift was varied using an adaptive procedure. They conclude that this new test provides a simple, quick and robust way to measure sensitivity to the TFS of complex tones.
Conclusions
It has been widely believed that temporal ENV is most important in speech intelligibility in quiet. However, temporal ENV information can be easily degraded in noise. As described above, TFS information can be useful for speech perception in background noise (especially in modulated noise) as well as pitch/melody perception. However, hearing-impaired listeners have reduced sensitivity to TFS, and fail to benefit from TFS information. Thus, in auditory rehabilitation field, attempts have been made to enhance the use of TFS information in hearing-impaired listeners. Compensation for TFS deficits in cochlear hearing loss could be achieved with continuous researches in the near future.