Introduction
Background noise often leads to difficulties of speech communication for both normal-hearing (NH) and hearing-impaired (HI) listeners. Especially for the elderly with hearing impairment, speech understanding in noise has been a common problem of daily communication despite a use of modern digital hearing aids [1]. As factors contributing to the speechunderstanding problems of older adults, a working group of the Committee on Hearing and Bioacoustics and Biomechanics of the National Research Council of the United States reported the peripheral hearing sensitivity, age-related decline in central-auditory and general cognitive functions [2]. Since this, numerous studies have determined various explanatory factors affecting speech-in-noise recognition difficulties. Some studies reported that an individualŌĆÖs peripheral hearing sensitivity was the most dominant factor predicting speech recognition performance in noise [3,4] while others found some suprathreshold functions such as temporal resolution as critical [5]. Furthermore, some researchers argued that working memory capacity appeared to be important for explaining the speech-in-noise recognition performance for NH listeners [6] and HI listeners [7]. These previous findings have mostly adopted a cross-sectional design based on group comparison (i.e., comparison between young NH adults and elderly HI (EHI) listeners, comparison between younger and older adults whose audibility is matched, or comparison among the elderly with or without hearing loss).
Since the previous studies on the age-related deficits in the speech-in-noise performance applied different methodologies, results varied depending on the criteria to recruit the listener groups, the type of test, and the degree of task demand. Given the discrepancies across findings, some researchers attempted to review earlier research to find any consistent evidence. For example, Humes and Young [8] qualitatively evaluated 34 published articles and revealed multimodal sensory-cognitive interactions among older adults, supporting a link between declines of sensory and cognitive functions. They emphasized a need of more research to better determine the nature of the link. Akeroyd [9] reviewed twenty experimental studies that addressed the relationship between some cognitive aspect and speech recognition in noise mostly for older HI listeners. The author found that a variety of cognitive and speech tests was used across 20 studies and that the cognitive aspects seemed to be linked to the speech perception. However, there was no one strong cognitive test that could always predict speech-understanding performance across numerous studies, and the middle-aged listeners were rarely included as a listener group. F├╝llgrabe and Rosen [10] conducted a meta-analysis and cautioned not to generalize the relations between working memory and speech-in-noise recognition independent of listenersŌĆÖ age and hearing loss.
Although hearing loss is highly prevalent in the elderly, several previous studies have included older adults with audiometrically normal hearing, which may not represent performance of older adults with typical presbycusis. When determining age-related declines in the earlier studies, a lack of inclusion of middle-aged listeners was often observed. Also, the various types of speech and cognitive tests have been conducted on the sensory-cognitive interactions. Although this aims to observe what can be the best test, it may be hard to implement various laboratory tests in a time-efficient way to examine sources of highly individual factors in speech-innoise difficulties. These limitations above have led further research on the factors contributing to speech-in-noise performance for both NH and HI listeners with a wide range of age (younger, middle-aged, and older listeners). Considering the practical importance of the results, this study executed clinically applicable tests to measure listenersŌĆÖ sentence-in-noise recognition, short-term auditory working memory span, and temporal resolution abilities. The present study attempted to explore factors predicting sentence-in-noise recognition performance with separate analysis of NH and HI listeners.
Subjects and Methods
Participants
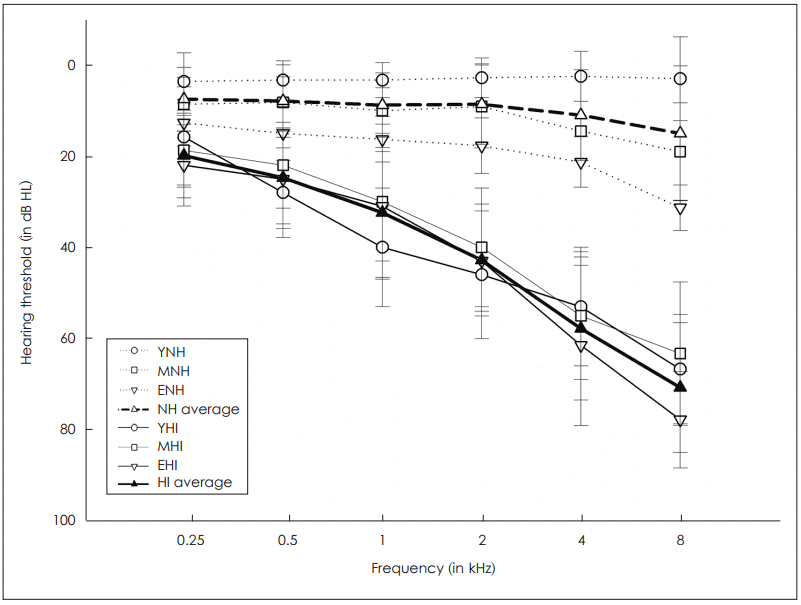
Forty NH listeners (13 males, 27 females) and 34 HI listeners (20 males, 14 females) participated for experimental testing. Among 40 NH listeners, 18 listeners were younger NH (YNH; mean age=25 years, age range=23-29 years), 11 listeners were middle-aged NH (MNH; mean age=52 years, age range=42-58 years), and 11 listeners were the elderly NH (ENH; mean age=68 years, age range=63-73 years). Considering the distributions of hearing thresholds as a function of age [11,12], the criterion of the NH listeners for study inclusion was the individual hearing thresholds equal to or less (better) than 25 dB HL at frequencies from 250 to 4,000 Hz at the octave scale. The mean hearing threshold of 40 NH listeners was 7.5, 7.9, 8.8, 8.6, 11, and 15 dB HL in the octave-scale frequencies from 250 to 8,000 Hz. The mean word recognition score (WRS) in quiet for the NH group was 95% (range=88-100%), suggesting no substantial difficulty in recognizing words in quiet.
Among 34 HI listeners, 6 listeners were younger HI (YHI; mean age=32 years, age range=24-35 years), 12 listeners were middle-aged HI (MHI; mean age=51 years, age range=40-59 years), and 16 listeners were EHI (mean age=69 years, age range=60-80 years). All the HI listeners had symmetric mild-to-moderate hearing loss without any middle-ear pathology, and their individual hearing thresholds were greater than 30 dB HL at 2,000 Hz and greater than 35 dB HL at 4,000 Hz. The mean hearing threshold of test ear for the HI group was 20, 25, 32, 43, 58, and 71 dB HL in the frequencies from 250 Hz to 8,000 Hz at the octave scales. The mean WRS in quiet for the HI listeners was 76% (range= 36-96%). Fig. 1 displays the mean hearing thresholds of NH and HI listeners based on their age, as well as the mean thresholds collapsed across the NH (n=40) and HI (n=34) listeners. All the elderly participants had no signs of dementia based on the score for the Mini-Mental State Examination [13,14]. All the participants completed the informed consent form before the experiment (IRB No. HUGSAUD627541).
Stimuli and procedure
The current study conducted three types of evaluations with clinical applicability: the sentence-in-noise recognition test, the gap detection test to evaluate auditory temporal resolution, and the digit forward and backward span test to measure short-term working memory.
For the measure of sentence-in-noise recognition, the sentences of the Korean Standard Sentence Lists for Adults [15] were presented in multitalker babble noise at 0 dB signal-tonoise ratio (SNR). The sentence-in-noise recognition performance was scored by the percentage of key words correctly identified. The ability of auditory temporal resolution was evaluated by gap detection performance using the Gaps-In-Noise (GIN) test [16]. In the GIN test, subjects listen to 6 sec segment of broadband noise that contains 0-3 silent gaps, and each gap ranging from 2 to 20 msec in duration is repeated six times within each list. ListenersŌĆÖ gap detection performance was measured by determining the shortest gap duration where a subject correctly identified at least four out of six gaps. Results of the GIN test were recorded as overall percentcorrect score across all gap durations. Prior to the experimental test, a practice test of GIN was provided. Lastly, a listenerŌĆÖs working memory span was measured by tests of forward and backward digit span, one of the oldest and most widely used neuropsychological tests as a general measure of short-term working memory [17]. Digit forward is known to primarily involve the short-term auditory memory processes whereas digit backward involves the additional components of attention [18]. The current study measured the digit forward and backward spans using live-voice presentation at a rate of about one digit per second. To obtain the digit forward span, the participant was asked to recall digit sequences in the exact order as they were presented (forward order). On the digit backward span, the listener was required to recall the digit sequences in the reverse order or presentation. Participants received two trials beginning with a length of two digits (9 digits as maximum). The digit span test stopped when the subject failed to correctly report either trial at each sequence.
For all measures described above, each subject was seated in a double-walled sound treated booth. All the stimuli were presented at each listenerŌĆÖs most comfortable listening level, and were delivered through a diagnostic audiometer (GSI 61; Grason-Stadler, Eden Prairie, MN, USA) and a loudspeaker located at 0 degrees azimuth nearly 1 meter. The root-meansquared value of each stimulus and background was controlled via Adobe Audition┬« (version 3.0; Adobe Systems Incorporated, San Jose, CA, USA) to equalize the overall intensity. The output level was periodically checked by the experimenter during testing.
Data analysis
Based on the mean WRS in quiet for the NH and HI participants (NH=95%, HI=76%), it would be not surprising to examine the poorer performance of HI listener than that of NH listeners. To examine whether sentence-in-noise recognition, temporal resolution, and short-term working memory would be affected by age for both NH and HI listeners, the current study executed one-way analysis of variance analyses for the NH and HI listeners separately, with an independent variable of age. The dependent variables were sentence-innoise recognition, GIN percent-correct score, and digit forward/backward span. The multiple post-hoc comparisons were conducted if needed. The relations of the sentence-in-noise recognition with short-term working memory and temporal resolution abilities were examined by the Pearson correlation analyses. To examine best predictors of the sentence-in-noise recognition scores, the stepwise multiple regressions estimated contribution of listenersŌĆÖ age, high-frequency hearing sensitivity [puretone threshold average (PTA) across 1, 2, 4 kHz], digit forward/backward span, and the GIN score. All the analyses were conducted using SPSS version 19.0 (SPSS Inc., Chicago, IL, USA). A significance level of p<0.05 was employed in our study.
Results
Measurement of sentence-in-noise, auditory temporal resolution, and short-term working memory
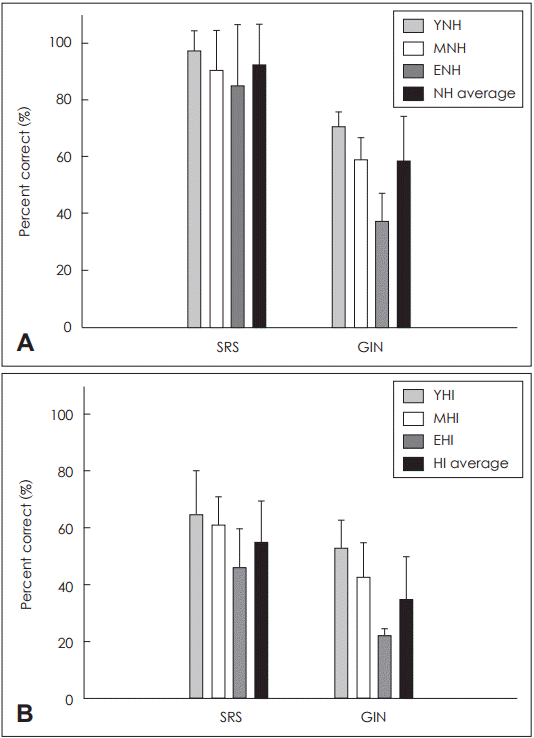
The panels of Fig. 2 show the mean score of sentence recognition scores (SRS) in noise and the mean score of GIN for the NH (Fig. 2A) and HI (Fig. 2B) groups, separately. As shown in the Fig. 2A, the mean SRS of the YNH, MNH, and ENH listeners was 97.4%, 90.4%, and 84.9%. The overall SRS collapsed across 40 NH listeners was 92.0% (┬▒14.9, range=37-100%). Statistically, the abilities of sentence-in-noise recognition did not differ among YNH, MNH, and ENH listeners (p>0.05). This suggests that the NH listeners, regardless of age, have a fairly good performance at least for 0 dB SNR condition used in this study. Compared to the NH listeners, the HI listeners performed poorer, as expected. As plotted in the Fig. 2B, the mean SRS was 64.8%, 61.3%, and 46.1% for the YHI, MHI, EHI listeners, respectively. The overall SRS averaged over 34 HI listeners was 54.8% (┬▒14.9, range=20-84%). Among the HI listeners, the EHI listeners showed significantly (p<0.05) poorer SRS compared to the MHI or YHI listeners, yet the SRS of the MHI and YHI adults was similar.
The mean percent-correct score of GIN was 70.9%, 59.0%, and 37.2% for the YNH, MNH, and ENH listeners, respectively. Their overall score of GIN was 58.4% across NH listeners (┬▒15.8, range=22.5-77.5%). The results of multiple comparisons showed that the YHI listeners poorly detected gaps than MHI listeners who were poorer than YHI (p<0.05). For the HI listeners, the mean GIN score was 52.8%, 42.5%, and 22.2%, for the YHI, MHI, and EHI listeners, respectively. The overall score of GIN was 34.8% across the HI listeners (┬▒15.0, range=17-62.5%). Based on the normative data of GIN (cut-off value of 62% for percent-correct index) [16], the overall GIN score of ENH listeners and the scores of all the HI listeners were relatively lower. Statistically, the GIN scores of the HI listeners were significantly (p<0.05) affected by age, and the results of the multiple comparisons revealed that the EHI listeners detected gaps poorly compared to the MHI or YHI listeners.
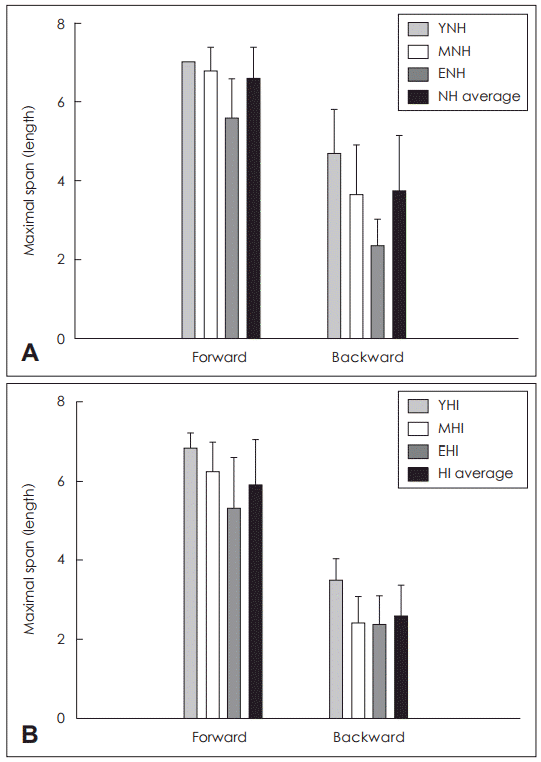
The panels of the Fig. 3 show the mean digit forward and backward span for the NH (Fig. 3A) and the HI (Fig. 3B) groups, separately. For the NH listeners, the mean digit forward span was 7, 6.8, and 5.6 (total average=6.6┬▒0.8, range=4-7) and the mean digit backward span was 4.7, 3.6, and 2.4 (total average=3.8┬▒1.4, range=1-7) for the YNH, MNH, and ENH listeners, respectively. For the HI listeners, the mean digit forward span was 6.8, 6.3, and 5.3 (total average=5.9┬▒1.2, range=3-7) and the mean digit backward span was 3.5, 2.4, and 2.4 (total average=2.6┬▒0.8, range=1-4) for the YHI, MHI, EHI listeners, respectively. The statistical results revealed similar trend for NH and HI groups. Results of the multiple comparisons showed that digit forward and backward spans did not differ between younger and middle-aged listeners. For both ENH and EHI groups, the older listeners had lower digit forward and backward spans compared to the middle-aged or younger group (p<0.05).
Factors affecting sentence-in-noise recognition performance
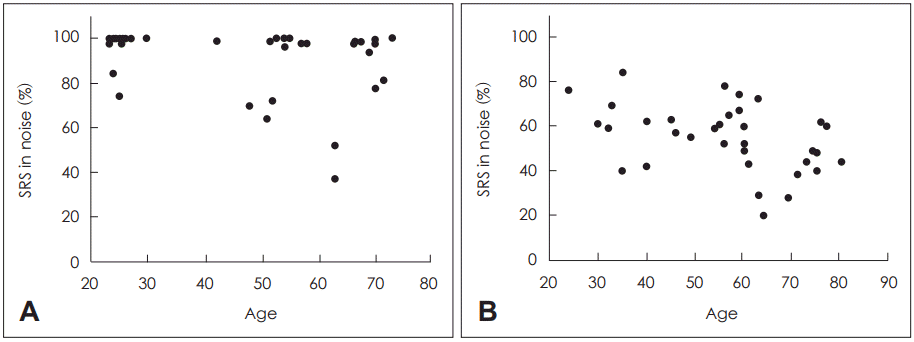
Since the age range was large for NH (23 to 73 years of age) and HI listeners (24 to 80 years of age) and each group showed a large individual variance on the SRS, the individual SRS in noise was plotted as a function of participant age for the NH (Fig. 4A) and the HI (Fig. 4B) groups. As shown in the Fig. 4A, the individual variability in sentence-in-noise recognition performance was hardly predicted by age of NH listeners (p>0.05). However, the individual SRS in noise of the HI listeners was significantly related to their age (Pearson correlation coefficient r=-0.4, p>0.05), as displayed in the Fig. 4B.
Given a greater variability in the sentence-in-noise recognition score, Pearson correlation analyses were also executed to examine whether the listenerŌĆÖs sentence-in-noise recognition would be related to their short-term working memory, temporal resolution abilities, and other demographic information. The correlation analyses were computed for NH and HI listeners separately. For the NH individuals, the SRS in noise showed a significant (p<0.05) correlation with digit forward (r=0.32)/backward span (r=0.39) and high-frequency hearing sensitivity (r=-0.35), but no relationship with their age or temporal resolution abilities. This indicates that age alone might be insufficient to explain individual variance in sentence-innoise recognition of the NH listeners. For the HI listeners, the SRS in noise were significantly (p<0.05) related to the temporal resolution as measured by the GIN test (r=0.59), the highfrequency hearing sensitivity (r=-0.46), and the digit forward span (r=0.40), yet unrelated to the digit backward span.
Based on the differential correlation results for sentencein-noise performance between groups, the stepwise multiple regression analyses were administered to determine best predictors accounting for variances of the sentence-in-noise difficulties for NH and HI listeners separately. The entered independent variables were age, high-frequency hearing sensitivity (PTA across 1, 2, 4 kHz), digit forward/backward span, and GIN percent-correct score, with a dependent variable of the sentence-in-noise recognition score. Table 1 shows the results of multiple regression analyses. Results showed that, for NH listeners with a wide age range, only the digit backward span was retained as a predictor variable in the regression equation, accounting for about 13% of the variance (adjusted r2=0.13) in the sentence-in-noise scores. No other predictors were found. For the HI group, results of the regression analyses revealed that the GIN score explained 33% of the variance in their sentence-in-noise scores. The GIN score and the highfrequency PTA together accounted for 39% of the variance in the sentence-in-noise scores of the HI listeners.
Discussion
The present study aimed to determine the primary predictive variables for the sentence-in-noise performance of NH and HI listeners. Not surprisingly, the results revealed poorer performance of the HI listeners on the sentence-in-noise recognition, auditory working memory, and auditory temporal resolution compared to NH listeners, supporting the previous findings on the poorer performance of HI listeners [19-21]. Rather than a group comparison, the present study focused on the differential roles of variables in prediction of the sentence- in-noise recognition for NH and HI listeners. For the NH listeners, either their age or hearing sensitivity alone could not fully explain their sentence-in-noise difficulties. Rather, the digit backward span emerged to be a best predictor accounting for the individual variances in the speech-in-noise understanding difficulties. This could be possibly because the audiometric hearing thresholds of the NH listeners were near normal up to 4 kHz and we presented materials at individualŌĆÖs most comfortable level. This suggests that when the target speech is sufficiently audible to NH listeners, their age, hearing sensitivity, and suprathreshold temporal resolution are not predictive of their speech-in-noise perception. Rather, the cognitive capacity such as short-term working memory and attention may play a key role when predicting speech-in-noise difficulties. Similar to our data, Schoof and Rosen [22] found that older listeners with near-normal hearing did not necessarily perform poorly on speech-in-noise recognition task unless a very demanding condition like two-talker noise was not involved. Humes, et al. [23] revealed the important roles of the age-related cognitive factors especially when the listening conditions and tasks became difficult requiring more processing strategies and listening efforts.
The current study measured the digit forward and backward spans, being known to have different memory processes [24]. For the digit forward span task, listenersŌĆÖ information storage is important while the digit backward span task requires both the storage and processing components. Since the digit backward span involves more complex cognitive processing, digit backward span has been used as a marker for possible cognitive deficits compared to relatively simple task [24]. Although the role of working memory capacity was presumed to be more apparent with complex stimuli and tasks, we found that the digit backward span was predictive of speech-in-noise performance in NH listeners. This suggests, at least when the audibility is ensured, the speech-in-noise understanding may be associated with the listenersŌĆÖ information storage as well as processing capacity. Since the speech-in-noise understanding was assessed by a simple task of sentence repetition in the current study, more studies are needed to examine the speechin-noise understanding problems of the NH individuals with varying the task demand and the complexity of stimulus.
For the HI listeners, age, high-frequency hearing sensitivity, digit forward span, and GIN score were all related to their speech-in-noise performance. Results revealed a widely varying ability in sentence-in-noise recognition, gap detection in noise, and working memory performances for HI individuals. The large variance in the sentence-in-noise recognition difficulties was accounted for by declines in their high-frequency hearing sensitivity as well as suprathreshold temporal resolution. This is because, especially for the listener with deteriorated hearing sensitivity, it requires more work and efforts of the bottom-up systems to encode the target speech signal while ignoring noise and then relate the decoded information to stored knowledge. The current finding supports that the peripheral sensitivity and the auditory temporal resolution are important predictive variables of the sentence-in-noise problem for the HI listeners, consistent with some previous studies [21,25-30]. For example, Cervera, et al. [21] reported that the listenersŌĆÖ hearing sensitivity was critical to explain the performance difference between young and young-elderly groups on the working memory capacity and processing of fast speech. In agreement with that, Carroll, et al. [25] conducted word-monitoring and comprehension tests and found that hearing impairment resulted in sentence processing difficulties, making more effortful perceptual processing. A review on the existing research reveals that cochlear hearing loss is associated with temporal encoding and processing, presumably affecting perceptual difficulties in HI listeners [26]. The authors emphasized a need of more research on the effects of hearing loss on temporal coding in the background noise and relation to the speech perception.
The present study has several limitations including a small sample size for each age group as well as use of a few simpletask evaluations. The exact contribution of working memory to the large individual differences in the speech-in-noise perception remains still unclear especially for the challenging listening situations. Taken this, future studies need to determine the factors predicting speech-in-noise performance using more complex stimuli and task.
In conclusion, the current study found differential predictive variables of the sentence-in-noise recognition abilities for NH and HI listeners. For the NH listeners, the ability of complex cognitive processing better explained their sentencein-noise recognition difficulties. For the HI listeners, loss of peripheral sensitivity and auditory temporal resolution could be the sources of speech-in-noise difficulties. This suggests that the primary explanatory factors for the sentence-in-noise recognition performance differ between NH and HI listeners. Considering this, we must be careful not to generalize findings from the NH individuals to the HI population.