Introduction
Speech is a complex sound and can be analyzed by the intensity and frequency. These acoustic features of speech sound depend on gender, phoneme, content of conversation, and emotion. It is reported that males generally conduct much lower sound than females do and adults conduct much lower sound than youth do [1]. The average fundamental frequency (F0) of the articulation of adults is 222.9 Hz [2], with the averages of F0s of female and male are 216.7 Hz and 112.1 Hz, showing 1.8 times higher frequency in female [3]. In a reading distance of 15 cm from a microphone, the mean intensity of person’s speech was measured at 69.3 dB SPL [4], and the mean intensity of conversation was measured at 50 to 70 dB HL in general [5]. To be heard comfortably across speaking environments, it should be ranged from 63 to 80 dB among normal adults [6].
Acoustic features of phonemes are also dependent on gender and emotional statuses. For example, F0s of /a/, /i/, and /o/ were 127, 143, and 129 Hz in male and 214, 230, and 215 Hz in female, respectively [7]. Other than F0, the characteristic of frequency of vowel can also be described by the vowel chart with the vowel trapezium. Three categories, high, middle, low vowels are classified by the tongue position when a speaker articulates corresponding vowels. High vowels are /i/, /u/, /e/, and /ʊ/, middle vowels are /o/, /ɪ/, and /ɚ/, and low vowels are /a/, /ɛ/, /ʌ/, and /æ/, with International Phonetic Alphabet symbols. The intensities of /a/, /i/, and /o/ were 78.5, 77.5, and 80.2 dB in male, 73.2, 72.3, and 75 dB in female, at a recording distance of 10 cm from a microphone [7].
The emotional status is one of the factors that can change acoustic features because of prosodic features of the different emotions. Yildirim, et al. [8] investigated acoustic properties of sentences uttered by a semi-professional actress associated with four different emotions such as sadness (S), anger (A), happiness (H), and neutral (N). The means of F0s were 188, 195, 233, and 237 Hz for N, S, A, and H. Authors suggested that the positioning of tongue for speech production can possibly differentiate frequencies for the various emotional statuses. They concluded that happy/anger and neutral/sad share similar acoustic features. Higher pitch and wider energy values were found in happy and anger emotions. This phenomenon was exhibited not only in speech samples but also in phonemes [9].
The Ling 6 sounds were composed of /u/, /a/, /i/, /sh/, /s/, and /m/ [10]. As six sounds have concentrated energies across the speech frequency range from 250 Hz to 8,000 Hz, identification of these sounds is known to be meaningful in estimating hearing thresholds at relevant frequencies for children. In Korean, the average of /u/ was measured at 300 Hz with the range from 284 Hz to 519 Hz, /a/ at 1,500 Hz with the range from 659 Hz to 2,314 Hz and /i/ at 3,200 Hz with the range from 2,046 Hz to 3,367 Hz, and /sh/ and /s/ were measured at about 4,000 Hz to 6,000 Hz [11]. Although the frequency range of those words covered from 250 Hz to 8,000 Hz which was thought to be the usual speech frequency range [12], the frequencies of individual words, specially the vowels showed different frequency values across the languages [13-15]. And if the emotional and gender factors are added, the variability could be more complicated. Nevertheless, these sounds are widely used as a fast and easy assessment tool for both hearing check and estimation of speech perception area for the aural rehabilitation process for children, the acoustic features of these sounds are of interest among researchers.
The cortical auditory evoked potentials (CAEPs) including P1, N1, P2, and N2 is also called the long latency auditory evoked potentials, as it typically measures the electrical activity that occurs in the central auditory system at about 50 ms after stimulation. The normal presence of CAEP components indicates that the signal was encoded in the auditory cortex properly. Also, these can reflect the neural activity of the brain at the different levels. Out of the components of CAEP, P1 represents the activity of secondary auditory cortex and Heschl’s gyrus in the auditory cortex and N1 represents the activity of primary auditory cortex by the activities of left and right hemispheres [16]. Therefore many investigations were performed to verify the origins presuming higher central nervous system and to compare the responses of the normal hearing to the patients with autism, attention deficit disorder, and hearing impairment [17,18]. Different acoustic features are valuable factors for analyzing CAEPs showing larger amplitudes when using speech stimuli than when using tone bursts implying superior cortical processing of the speech stimuli [19]. Further, components of CAEP were generally affected by the intensity and frequency of the stimuli. As the intensity and frequency increases, the amplitude increases and the latency decreases with tonal stimuli [20]. With speech stimuli, the intensity effect remained identical [21,22], while the frequency effect was scarcely known since speech stimuli were composed of multi frequency components. Interestingly, it was reported that N1 latency decreased as F0 increased for complex stimuli when the frequency was more than 62.5 Hz apart [23]. A previous research reported N100m which is thought to be N1 component in CAEP can be changed by different vowels such as /a/, /i/, and /e/, because of different acoustic features [24]. Conclusively, CAEPs can be utilized as objective indicators of changes to acoustical features of speech including vowels. And these results can let us have more comprehensive knowledge about central auditory nervous system with decoding speech.
The purpose of this study was to evaluate and analyze the acoustic features according to four emotions, N, A, H, and S of three vowels, /u/, /a/, and /i/ out of Ling 6 sounds. These vowels were selected as /u/, /a/, and /i/ representing low, middle and high frequencies of hearing and core vowels for rehabilitation. Especially, the frequency of those vowels were different across the languages, identifying Korean frequency ranges of those vowels would be meaningful for better use of Ling 6 sound. We hypothesized that frequencies and intensities out of several acoustic features be changed by gender, emotional statuses and vowels themselves. Additionally, as CAEPs be different according to different vowels for reflecting the acoustic features of /u/, /a/, and /i/, the CAEPs were explored for identifying as possible objective windows of the corresponding vowels.
Subjects and Methods
A total of 20 young adults, 10 males and 10 females (mean: 22.1, standard deviation: 2.17) produced /u/, /a/, and /i/ vowels according to emotions of A, H, S, and N. The subjects watched relative emotional screens for 4 to 5 minutes prior to producing vowels so that they can draw their empathy for production of vowels for the corresponding emotions. The videos were selected in the Youtube. N was recorded without watching the video. An angry emotion was induced right after watching the video about animal abuse (https://www.youtube.com/watch?v=olDsYSou7fQ), a happy emotion was induced right after watching the video about fun tumbling mistakes which make people laugh (https://www.youtube.com/watch?v=u3XWq63IMFE), and a sad emotion was induced right after watching the video about regretting for not being nice for parents (https://www.youtube.com/watch?v=p-qZ76akjkE). Considering, the age of subjects, category, and checking numbers, the specific videos were chosen for inducing appropriate emotions when producing vowels from the group of investigators.
The participants produced a sentence including the target vowel for consistent analysis of vowel sound part. For example, “I speak /a/” sentence was recorded for the target vowel /a/. The production of vowel part of sentence was sustained for 2 seconds. Only well-recorded portion was extracted for 500ms in order to control the quality of the data. When each recording session was finished, a 3 minutes break was given to the participant for separating the emotional status from the last record. The device used for recording and analysis was the main program of Computerized Speech Lab (CSL) (KayPENTAXTM, Lincoln Park, NJ, USA). Also, Multi-Dimensional Voice Program (KayPENTAXTM, Lincoln Park, NJ, USA) was used to identify the normal range of hoarseness and vibration of the production. Also, the confusion matrix was evaluated to find out how effectively the acoustic features discriminate emotions. 10 young adults, 5 males and 5 females (mean: 23.8, standard deviation: 2.11), participated for evaluation of confusion matrix. Twenty sets of stimuli composed with 5 of 4 emotional sorts were evaluated for each vowel. The participants selected the emotions that they think they heard. Then their selections were matched for the correct emotions provided.
Pure tone audiometry was performed to all participants for confirming normal hearing prior to the CAEP measurements. The CAEP responses were measured from 18 normal young adults, 9 males and 9 females, with age average of 22.3 (male: 22.6, female: 22.0). Bio-logic Navigator Pro System (Natus, Mundelin, IL, USA) was utilized as an experimental device. Out of recorded production of vowel sounds, neutral recordings of /u/, /a/, and /i/ vowels were selected for this experiment. The closest mean frequency and intensity productions of male and female were used. Male participants listened recorded vowel sounds of male and female participants listened recorded vowel sounds of female as stimuli. Acoustic features of vowel used to CAEP for male and female were shown in Table 1. The stimulus was presented at 70 dB HL using rarefaction polarity with the rate of 0.7 stimuli per second. 150 responses were taken for each recorded vowel. Electrodes were attached in two channels with gold cup electrodes, noninverting electrode was attached to Fz, common to Fpz, and inverting electrode, to both right and left mastoids. The bandpass filter was from 1 to 30 Hz and gain was 10,000 for both channels. CAEP’s components, P1, N1, P2, N2, and amplitude of N1-P2 complex were measured.
For analyzing acoustic features of vowels statistically, the independent variables were 3 vowels, /u/, /a/, and /i/, 4 emotions, N, A, H, and S, and gender, male and female. The dependent variables were intensity and frequency of the vowels. Three ways mixed analysis of variance (ANOVA) was utilized for the statistical analysis. For the CAEP experiment, independent variable was 3 vowels, /u/, /a/, and /i/ and the dependent variables were latencies and amplitudes of the components of CAEP. One way ANOVA was utilized for the statistical analysis. The statistical package for the social sciences version 20.0 (IBM Corp., Armonk, NY, USA) was applied and the statistical analysis conducted at significant level of 0.05. The study was approved by the Institutional Review Board of Hallym University (HIRB-2015-090). The informed consent form was reviewed and approved by the IRB.
Results
Acoustic features
Intensities were 62.29 dB and 61.31 dB for the male and female voices. Although the production of male participants showed stronger intensity than that of female participants with the difference of 0.982, there was no statistical significance (p>0.05). Additionally, spectrograms showed wider intensity range for the female’s voice (Fig. 1).
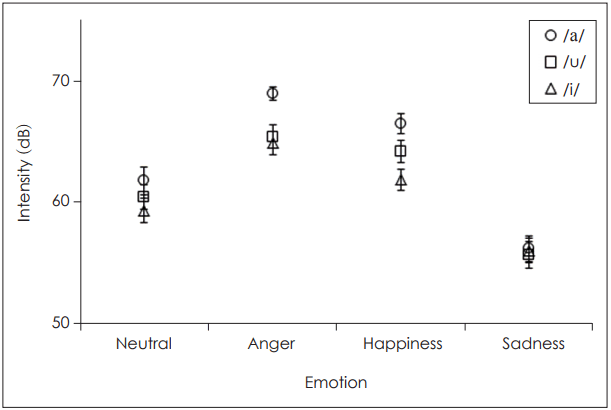
Intensities of /u/, /a/, and /i/ were 61.47 dB, 63.38 dB, and 60.55 dB, revealing the highest intensity at /a/ and the lowest intensity at /i/ with the statistical significance (p<0.05) (Table 1, 2), respectably. A Bonferroni post hoc test indicated that intensity of /a/ was significantly different from /i/ (p<0.05). The intensities by emotions of N, A, H, and S were 60.54 dB, 66.44 dB, 64.21 dB, and 56.01 dB revealing the highest intensity with A and the lowest intensity with S showing the statistical significance (p<0.05). The strongest intensity was recorded with A followed by H, N, and S in the order. Interaction effect showed the statistical significance between vowel and emotion (p<0.05) (Fig. 2). The highest intensity was recorded by /a/ with A in the female’s production.
Frequencies of the produced vowels were analyzed by the F0, the first formant (F1), the second formant (F2), and the third formant (F3) sequentially (Fig. 3). F0s were 139.12 Hz and 198.60 Hz for the male and female voices with the statistical significance (p<0.05). F0s of /u/, /a/, and /i/ were 171.69 Hz, 161.35 Hz, and 173.54 Hz with the statistical significance (p<0.05). A Bonferroni post hoc test indicated that F0s of vowels were significantly different in the pairs of /a/-/i/ and /a/-/u/ (p<0.05). F0s of N, A, H, and S were 168.04 Hz, 174.93 Hz, 182.72 Hz, and 149.76 Hz with the statistical significance (p<0.05). A Bonferroni post hoc test indicated that F0s of vowels were significantly different between S and the rest of emotions (p<0.05) (Table 3).
F1s were 730.45 Hz and 793.69 Hz for the male and female voices, respectively, with no statistical significance (p>0.05). F1s of /u/, /a/, and /i/ were 740.55 Hz, 1,096.58 Hz, and 449.07 Hz with the statistical significance (p<0.05). A Bonferroni post hoc test indicated that F1s of vowels were significantly different for pairs of /a/-/i/, /a/-/u/, and /i/-/u/ (p<0.05). F2s were 3,146.93 Hz and 3,241.85 Hz for the male and female voices with no statistical significance (p>0.05). F2s of /u/, /a/, and /i/ were 3,761.80 Hz, 2,975.15 Hz, and 2,846.20 Hz with no statistical significance (p>0.05). F2s were 3,345.52 Hz, 2,987.79 Hz, 3,014.26 Hz, and 3,429.97 Hz for N, A, H, and S with no statistical significance (p>0.05). F3s were 5,065.51 Hz and 4,906.35 Hz for the male and female voices with no statistical significance (p>0.05). F3s of /u/, /a/, and /i/ were 5,858.29 Hz, 5,051.93 Hz, and 4,047.57 Hz with the statistical significance (p<0.05). The Bonferroni with post hoc test indicated that the statistical significance between /i/ and the others. F3s were 5,083.74 Hz, 4,519.23 Hz, 4,789.74 Hz, and 5,550.99 Hz for N, A, H, and S with the statistical significance (p<0.05) (Fig. 3).
The confusion matrix analysis was applied to evaluate the effectiveness of discriminating emotions (Table 4). The matrices indicated that the acoustic features were relevant to distinguish the corresponding emotion revealing 68-100% correction probability. Angry emotion expressed seemed harder to distinguish showing the lowest correction rate among emotions showing 68-80% correction rate while others showing 82-100% correction rate.
CAEPs
Each vowel revealed a different waveform in CAEP recordings. Fig. 4 shows average waveforms of CAEPs by vowels, /u/, /a/, and /i/.
P1 latencies and amplitudes of /u/, /a/, and /i/ were 43.67, 40.84 and 50.90 ms and 1.37, 1.40, and 1.33 μV. N1 latencies and amplitudes of /u/, /a/, and /i/ were 102.54, 96.93, and 104.92 ms and -2.97, -3.27, and -3.44 μV. P2 latencies and amplitudes of /u/, /a/, and /i/ were 177.32, 162.81, and 174.95 ms and 1.81, 2.52, and 2.14 μV. N2 latencies and amplitudes of /u/, /a/, and /i/ were 247.01, 247.39, and 252.97 ms and -1.30, -1.53, and -1.49 μV. The N1-P2 amplitude of /u/, /a/, and /i/ were 4.86, 5.90, and 5.60 μV (Table 5). Any of CAEP components did not show statistical significances for latencies and amplitudes according to vowels for both male and female. However general tendency could be observed by the intensity of stimulus. As the intensities increased (/i/</a/</u/), the latencies decreased and the amplitude increased. Any of the frequency characteristics did not affect to the latency and amplitude of CAEP components of this study.
Discussion
When vowel sounds of /u/, /a/, and /i/ representing low, middle, and high frequencies out of Ling 6 sounds were analyzed by CSL. The average intensity of the total was 61.80 dB showing similar result of 58.30 dB to the previous study [25]. Intensities for the male and female voices were 62.29 dB and 61.31 dB in the present study, showing similar results with previous studies [6,7]. In the present study, the intensity of /a/ was the strongest showing consistent results to the preceding research [7]. The order of intensity of this study was /a/, /u/, and /i/ while Brockmann, et al. [7] reported order of intensity as /o/, /a/, and /i/. As the present study did not include vowel /o/ and the other study did not include vowel /u/, we can conclude /a/ showed stronger intensity than /i/ consistently. When the intensities by emotions were compared, the intensity of A and H showed stronger than N and S for the present study and the preceding study [8].
The average of the F0s of the vowels of the present study was 168.86 Hz and the average of F0s of the sentence was 178.13 Hz in the previous investigation [26]. Both showed similar results. F0s for the male and female voices of this study were 139.12 Hz and 198.60 Hz and the preceding study showed the range 92.8-156.1 Hz for the male voices and 172.4-274.5 Hz for the female voices. All recorded about 79.6-118.4 Hz higher frequencies for the female voices. This phenomenon has been widely agreed among investigations, as many researches also reported that the vowel productions of the male were lower and stronger than those of the female [4,7,27]. The stronger intensity with lower frequency of the male voice can be interpreted by the size of the male’s vocal fold as many investigators explained [27,28].
The frequency of vowel in terms of F0 seemed to be affected by tongue position in oral cavity when the vowel was produced because /u/ and /i/ showed higher frequencies consistently across the investigations [28,29]. The fact that /u/ and / i/ are sorted as high vowels at the vowel chart which is classified by the characteristic of tongue position supports this issue. For example, F0s of /u/ and /i/ were 171.69 Hz and 173.54 Hz showing higher than 161.35 Hz of /a/ in the present study. Interestingly, the order of pitches of the vowel, /u/, /i/, and /a/ was found to be similar across the languages, although the frequencies of the vowels were affected by the linguistic characteristics. Whalen and Levitt [29] compared 32 different languages F0s of /u/, /a/, and /i/ and reported that they all showed different values. However, the order of pitches in frequency with /u/, /i/, and /a/ remained the same. Additionally, F1s and F2s of /u/, /a/, and /i/ seemed to be affected by different languages. When, French, German, Australian English and Korean with the results of the present study were compared for the female voices of F1, the largest difference was revealed in /a/ and the smallest difference was revealed in /i/ across the languages. But the higher frequencies in of /u/ and /a/ were also observed (Table 6) [13-15].
The highest F0 was revealed with H and followed by A, N, and S in the order. And these results were similar to the previous studies [8], although the researcher used different materials form this study, for example, short sentences and two-syllables. The order of emotions of F0s was not affected by different materials. Taken all together, both H and A seemed to show the highest intensity and frequency regardless of materials utilized. Possibly, the reason could be the expressive way of extreme emotions which had strong acoustic qualities. Because A and H situated opposite to each other in the pleasure axis, acoustic features were commonly observed strongly in other investigations [8,9].
The emotional matrix revealed that the average of correct rate was 87.9% of this study. This rate was higher than the value of 68.2% reported by the previous study [8]. This difference was thought to be due to the materials of the experiment between the vowels of this study and the sentences of the previous study.
Conclusively, subtle changes of acoustic features such as the intensity and frequency according to vowels and emotions should be considered when performing the Ling 6 sound test, although those sounds are within speech frequencies, 250-8,000 Hz. The speaker should be careful with the emotions when fitting the hearing aids and performing aural rehabilitations for children with vowels /u/, /a/, and /i/. Also, the gender of the speaker should also be considered. With the importance of the frequency range heard by children in the rehabilitation session, the consistency of the voice for Ling 6 sound test should be self-checked during the session. However, further investigation is recommended to evaluate the /m/, /s/ and /ʃ/ sounds in order to analyze the acoustic features of the whole Ling 6 sounds with emotions and gender.
For CAEPs, the vowels of this study did not show any statistical significance for the latency and amplitude for both male and female participants. However, general tendency of intensity was observed by the vowels, /u/, /a/, and /i/. As the intensity increased (/i/>/a/>/u/), the latencies decreased and the amplitude increased. The significant intensity effect was observed at the previous researches with more than 20 dB difference [21,22]. But the intensity difference was only 1.87 dB among the male’s vowel stimuli and 5.73 dB among the female’s vowel stimuli of this study. This would be the reason why there was no statistical significance depending on the intensity of the vowel stimuli for the present study. Also, N1 component which showed statistical difference in the frequency for the previous study [23] did not show any statistical significance in the present study. This discrepancy can also be explained by difference of the frequency utilized as materials. Because the research materials of the previous study had 62.5 Hz apart in frequency difference, while the materials of this study had less than 30 Hz apart among F0s vowels. For the reason, the frequency did not vary the latencies and amplitudes of CAEP components. The vowels used for this study seemed to act as tonal stimuli with tiny intensity and frequency differences. Therefore, the acoustic features of the vowels did not vary the latency and amplitude of CAEP components in the present study. However, some investigations observed that the spectral features of vowels reflected different source of locations of cortical responses meaningfully, when multichannel parameters or fMRI were utilized [30,31]. It was implied that the categorized cortical area represented activated locations in auditory cortex depending on different vowel stimulations. Further study should be performed with multichannel parameters for measurements and careful selection of materials including dramatic difference of the intensity and frequency for recording reflections of acoustic features of various vowels. The present study did not include the emotional factors of the vowel stimuli for CAEP measurements which may lead us for better understanding of the exogenous and endogenous components of the CAEP results. This is one of the limitations of the present study and the following experiment is being performed reflecting emotional salience of the vowel stimuli for measuring CAEP.