Introduction
The communication handicap imposed by sensorineural hearing loss influences the capability of a listener to understand speech in quiet as well as in competing background noise [1]. Although about 53.2% of the audiologists are reported to perform speech recognition testing in quiet along with other speech measures, only 9.5% of audiologists were reported to use speech-in-noise tests along with tests of recognition in quiet [2]. Compared to recognition of words in quiet, testing in background noise is considered to be more effective in showing performance difference among individuals with different degrees of hearing loss [3-5].
The stimuli used to measure speech identification in noise are diverse and includes stimuli such as syllables [6], monosyllabic words [6], sentences [7,8] and matrix sentences [9]. The signal-to-noise ratio (SNR) used for presenting stimuli also varies across studies, ranging from -15 dB [10] up to 24 dB [11].
Studies reporting an individualŌĆÖs performance in the presence of noise for different stimuli and SNRs are limited to English [3,5-8] and a few Indian languages [12]. Generalization of these data to Tamil speaking population is uncertain, besides which speech perception in noise test for clinical use is unavailable in Tamil language. The current study focused on evaluating the perception of mono-syllabic and bi-syllabic words in Tamil in the presence of multi-talker speech babble by young adults with normal hearing. The stimuli in the current study were selected from the existing word lists in Tamil that are frequently used clinically. Further, these words were used to construct the Speech-in-noise test in Tamil (SPIN-T). Hence, the performance of young adults with normal hearing in SPIN-T was evaluated. The study also assessed the phonemic error patterns observed during the speech identification in the presence of noise.
Subjects and Methods
SPIN-T used as the stimuli, was constructed as part of the current study using the available speech identification tests in Tamil. The test consisted of both mono-syllabic and bi-syllabic words at two SNRs (0 dB and +10 dB SNR) presented in the background of multi-talker speech babble. The two SNRs were selected in order to avoid ceiling or floor effect while testing speech perception in the presence of noise and also to evaluate which of the two SNRs may be clinically applicable to identify individuals with a deficit in perceiving speech in the background of noise.
Participants
Thirty young adults (15 males and 15 females) aged between 18 to 25 years (with a mean age of 20.4 years) participated in the study. All the participants had pure-tone hearing thresholds Ōēż15 dB HL at octave frequencies between 250 and 8,000 Hz. Only participants with ŌĆśAŌĆÖ type tympanogram with normal ipsilateral and contralateral acoustic reflexes at 500, 1,000, 2,000 and 4,000 Hz indicative of normal middle ear function were considered. All of them were native speakers of Tamil language without any history of speech and language difficulties, otological or neurological problems. Prior to initiation of testing, a written informed consent was obtained from all the participants. The methodology of the study was approved by Institutional Ethics Committee (REF No. CSP/ 16/JAN/45/45).
Stimuli
SPIN-T was constructed using existing mono-syllabic and bi-syllabic word lists. The Phonetically Balanced Test Materials in Tamil Language (mono-syllabic words) developed by Samuel [13] and the Picture Speech Identification Test for Children in Tamil (bi-syllabic words) developed by Boominathan [14] each with four lists comprised the stimuli of SPINT. These two materials [13,14] were chosen as stimuli for SPIN-T based on the availability and frequency of usage of existing wordlists in Tamil. These wordlists are widely used clinically for speech identification testing in quiet in Tamil speaking population. The bi-syllabic word list [14], though developed for testing children, was chosen with an assumption that words that were are familiar to children will also be familiar to adults. This assumption is supported by the findings of Borovsky, et al. [15] reported that word processing in adults and children varied in terms of speed of processing and vocabulary skill. They found age to be an insignificant factor associated with word processing [15]. Hence, the bi-syllabic word list [14], though developed originally for testing children, was chosen for testing adults. A female native Tamil speaker audio recorded these wordlists using the Computerized Speech Lab (CSL 4150 hardware; Kay Elemetrics Corp., Lincoln Park, NJ, USA) with SM 48 dynamic microphone at a sampling frequency of 44,000 Hz.
For generating the speech babble, a standardized passage in Tamil developed by Subramaniyan [16] was used. The passage consisted of 137 words with all the phonemes matched with the frequency of occurrence in Tamil language. Eight native speakers of Tamil, four male and four female audio recorded the passage independently. The recordings were carried out using the same procedure used for recording the word stimuli. The eight independent recordings were digitally mixed using the Adobe Audition (Version 3.0; Adobe Inc., San Jose, CA, USA) software to form the 8-talker speech babble. From the generated speech babble, 25 portions of 1 s and 1.2 s duration were segmented. The two durations (1 s and 1.2 s) were chosen based on the length of mono-syllabic and bi-syllabic word stimuli respectively. The background speech babble and the words were digitally mixed at two different SNRs (0 dB and +10 dB SNR) using Adobe Audition (Version CS 5.5; Adobe Inc., San Jose, CA, USA) software. The final SPIN-T test material consisted of four lists each of mono-syllabic and bi-syllabic words at 0 dB and +10 dB SNR. A 1,000 Hz calibration tone of 8 s duration was inserted at the beginning of the test. The waveforms of the stimuli with and without noise are depicted in Fig. 1.
Experimental procedure
A dual channel diagnostic audiometer (Piano-Inventis; Inventis, Padova, Italy) with TDH-39 headphones (Telephonics corporation, Farmingdale, NY, USA), B-71 bone vibrator and facility for routing signals through auxiliary input was used for testing the participants. Immittance evaluation to rule out middle ear pathology was carried out using an immittance audiometer (Flute-Inventis; Inventis, Padova, Italy). All the equipment were calibrated as per the recommendations of the manufacturers.
To determine the effect of SNR on perception of SPIN-T, it was administered on 30 participants who met the inclusion criteria. Additionally, error patterns exhibited by the young adults on the stimuli were also determined. The compact disk version of SPIN-T was routed through the auxiliary input of an audiometer and presented at 40 dB SL (re: PTA). Half the participants heard the stimuli in the right ear while the other half were tested in the left ear. The participants were instructed to write down the words as they heard them through the TDH-39 headphones (Telephonics corporation). Each participant heard a total of 4 lists of SPIN-T (2 lists of mono-syllabic words and 2 lists of bi-syllabic words, each at 0 dB and+10 dB SNR) consisting of 25 words each. The monosyllabic words list contained four individual lists while in the bi-syllabic word list the first two lists (List 1 and 2) were randomised to form lists 3 and 4. The order of presentation of the test stimuli (mono-syllabic and bi-syllabic), the list (Lists 1, 2, 3 and 4), SNR (0 and +10 dB) as well as the ear of testing (right and left) were randomised. This was done to avoid any order effect or ear effect.
Each correct response was scored as 1 while an incorrect response was scored as 0. The maximum possible score for each list of mono-syllabic and bi-syllabic word lists was 25. The total score obtained was calculated for each list at 0 dB and +10 dB SNR and tabulated. Additionally, the phoneme error patterns were coded for each incorrect response.
Statistical analysis was carried out using Statistical Package for the Social Sciences-SPSS software (version 18; SPSS Inc., Chicago, IL, USA). Both descriptive and inferential analysis were done. Prior to comparing the variables, Shapiro-Wilk test of normality was done to see if the scores were normally distributed. Since some of the variables did not follow normal distribution, non-parametric analysis was carried out, where p<0.05 was considered to be statistically significant. A Friedman test was done to compare the performance across four lists heard by each participant. Further, Wilcoxon signed rank test was done to compare the scores obtained for the two stimuli at the two SNRs.
Results
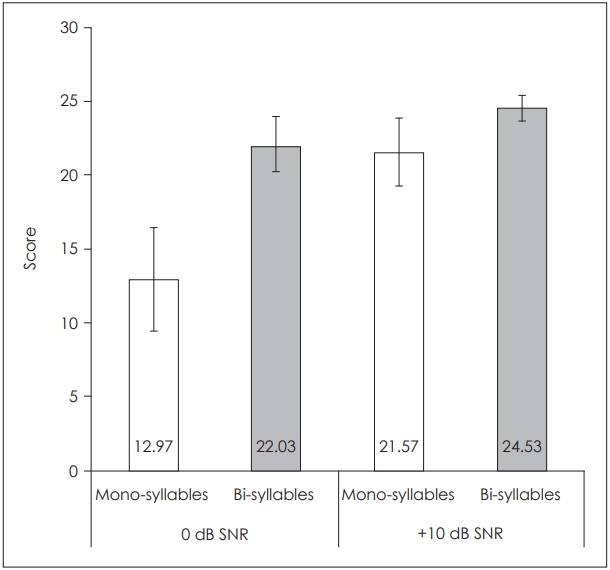
The current study evaluated the effects of SNR on speech perception in noise and the phoneme error patterns observed in the responses of SPIN-T. It was observed that the mean scores for both the mono-syllabic and bi-syllabic words lists was greater at +10 dB SNR as compared to those presented at 0 dB SNR (Fig. 2).
To evaluate if these differences in scores was significant a Friedman test was carried out. This showed a highly significant difference [Žć2 (3)=74.67, p<0.001] between the performance across the four lists (2 mono-syllabic and 2 bi-syllabic list at 0 and +10 dB SNR) each participant heard. Further, to assess if the performance at the two SNRs were statistically significant, Wilcoxon signed rank test was done. The results revealed a highly significant difference between the performances at 0 and +10 dB SNR for mono-syllabic (z=4.79, p<0.001) as well as bi-syllabic words (z=4.31, p<0.001).
Phoneme errors noted at the two SNRs for mono-syllabic and bi-syllabic words are depicted in Table 1 and 2. The mean and standard deviations of the errors in terms of place, manner and voicing in isolation and in combination are given in Table 1. Since the standard deviations were higher than the mean for most features that were considered, inferential statistics was not possible. Hence, the total number of errors was calculated (Table 2). However, since the comparisons between different error patterns were difficult, the total number of errors was converted to percentage for further statistical analysis.
It can be observed from Table 2 that the total number of errors was less at higher SNR (+10 dB SNR) for both monosyllabic and bi-syllabic words. It was also noticed that among the two stimuli, total number of errors was greatest for mono-syllabic words presented at 0 dB SNR. To aid in better comparison across the SNR and type of stimuli the total number of errors were converted into percentage.
From Table 2, it can be noticed that at the lower SNR (0 dB), significantly more errors were observed in place of articulation for both mono-syllabic and bi-syllabic words. However, at the higher SNR (+10 dB), percentage of errors was greater in manner of articulation for mono-syllabic words and place of articulation for bi-syllabic words. The second highest percentage of errors at 0 dB SNR was noticed in manner of articulation, followed by combination of place+manner error type for mono-syllabic words, it was vice-versa for bi-syllabic words. However, a different set of phoneme errors were noticed at the higher SNR. A combination of place+voicing errors was commonly noticed in mono-syllabic words whereas, for bi-syllabic words, listeners responded by adding a phoneme from the phonological neighbours of the target word. It can also be observed from Table 2 that ŌĆśno responseŌĆÖ (when the listener failed to repeat the word) contributed to a considerable percentage of errors, with the percentage being higher for mono-syllabic words presented at 0 dB SNR.
Discussion
The current study indicated better identification of monosyllabic and bi-syllabic word lists presented at +10 dB SNR when compared to 0 dB SNR in the presence of noise. These results are consistent with the findings of Beattie, et al. [17] who obtained similar mean scores for Central Institute for the Deaf, Test W-22 (CID W-22) mono-syllabic words in the presence of continuous multi-talker noise. Better performance at the higher SNR in the current study can be associated to better audibility of the speech stimuli at this SNR [5,11]. On the contrary, the poor performance observed for mono-syllabic words at 0 dB SNR finds support from the results of Hood and Poole [18] who attributed poor performance to limited availability of semantic cues for identification of these words in quiet. The availability of these cues may be presumed to be even more reduced in the presence of background noise leading to poor performance. Additionally, participants reported that although the words in mono-syllabic lists were familiar, their infrequent usage in day-to-day conversation posed difficulty in identification of these words in the presence of noise. As noted by Black [19], words that were more familiar to the listeners were found to be identified with greater accuracy, both in quiet and in the presence of noise, than words that were less familiar. Hence, the combined effect of infrequent usage and addition of noise could have drastically reduced the performance on these lists.
Mono-syllabic words were identified with better accuracy at +10 dB SNR compared to that at 0 dB SNR. Similar effect of SNR on perception of mono-syllabic words has also been reported by Studebaker, et al. [20]. Studying the effects of speech and noise levels on mono-syllabic words presented at 10 different SNRs from 28 to -4 dB SNR they found that the mean scores improved with increasing SNR up to 12 dB. Earlier, Gelfand, et al. [21] also reported better recognition of mono-syllabic words indicated by lesser number of errors at +10 dB compared to +5 dB SNR. Increase in the effective masking level of the speech signal was reported to be the reason for poor intelligibility at lower SNRs.
In the current study, unlike the performance on mono-syllabic words, the performance on bi-syllabic words was near the maximum possible score of 25 at +10 dB SNR. This indicates that the performance may not be very different form that observed in quiet for these words. As suggested by Beattie, et al. [17] the selected SNR for evaluating perception of speech in the presence of noise should avoid ceiling or floor effect. Hence, it was construed that the +10 dB SNR considered for bi-syllabic words, may not be helpful in identifying subtle difficulties in speech perception in noise because the scores at this SNR reached the maximum possible score for normal hearing listeners.
Further, analysing the phoneme errors of the SPIN-T responses it was found that the maximum percentage of errors was in place of articulation at 0 dB SNR for both mono-syllabic and bi-syllabic words (22.04% and 23.17% respectively). However, the pattern reversed at +10 dB SNR for monosyllables with more errors seen in manner of articulation. This indicates that the cues that transmit the place of articulation information including, formant frequency and spectral cues [22,23] are masked by the presence of speech babble, leading to the errors. Temporal cues required for the perception of manner of articulation [22] were relatively less affected by the presence of noise. Features transmitting place of articulation information was also reported to be poorly perceived by the young listeners identifying mono-syllabic words [21] in the presence of cafeteria babble. In addition, Alwan, et al. [22] stated that the type of background noise also had an effect on the cues available for perception. They speculated that speech-shaped or multi-talker babble noise could alter the formant frequency, which served as an important spectral cue for identification of the place of articulation [22]. As in the current study, multi-talker speech babble was used as background noise it could have led to masking of the spectral cues important for place of articulation perception. This masking effect may be aggravated at 0 dB SNR leading to poor scores for both mono- and bi-syllabic words.
In the current study, number of phoneme errors was observed to be greater at the lower SNR and when mono-syllabic words were used. Higher number of errors at more severe noise condition (low SNR and minimal availability of perception cues) was reported to be due to greater uncertainty of the target word [24]. Smith and Fogerty [24] stated that the phoneme errors were a result of phonetic confusions that arise in the presence of noise. They noted that listeners most likely substituted phonemes that resembled the target wordŌĆÖs phonological structure, irrespective of the level of noise [24]. These types of errors were also noted in the current study. For example, /╠¬tambi/ was part word substitution for /kambi/, the error sound also being a stop consonant. Additionally, they also found that phonemes omitted or added were also from phonological neighbourhood of the target word. For example, part word omission included /mee/ instead of /meen/ and part word addition was /ya:l/ instead of /ya:zh/. The different patterns of error according to Smith and Fogerty [24], were noticed because only limited acoustic-phonetic cues are available in presence of noise. Further, in the current study, a marked error that was noted was the ŌĆśno responseŌĆÖ. The participants tended to not respond when they were unsure of a response, resulting in such responses being maximum compared to any other feature errors especially for mono-syllables presented at 0 dB SNR. This is in concurrence with the observations of Smith and Fogerty [24] who also observed higher whole word omissions compared to part-word substitutions in the identification of sentences in the presence of speech-shaped noise.
In conclusion, the findings of the study indicate that speech identification in the presence of multi-talker babble is more challenging when compared to identification in quiet. This was inferred from the better performance observed at higher SNR for both mono- and bi-syllabic words. It was also found that bi-syllabic words are better identified than mono-syllabic words in presence of noise. Listeners tended to make more place of articulation errors compared to manner and voicing errors during identification of mono-syllabic and bi-syllabic words at the lower SNR. However, for mono-syllabic words at higher SNR, listeners exhibited a greater percentage of manner errors. Whole word omissions (no response) also contributed to be a sizable error type due to the non- availability of perceptual cues at severe noise conditions. It can be implied from the current study that, SPIN-T provides clinical impression about a personŌĆÖs ability to understand speech in the presence of noise. The use of mono-syllabic word list at +10 dB SNR and bi-syllabic word list at 0 dB SNR is recommended for clinical use. Additionally, SPIN-T can be helpful in making decisions about hearing aid selection when hearing aids show similar performance in quiet for speech. Compared to word recognition in quiet, SPIN-T may be more effective in showing the performance difference among individuals with different degrees of hearing loss.