Introduction
Digital noise reduction (DNR) is one of the features available in digital hearing aids (HAs) to reduce the negative impact of noise. Although DNR uses a variety of schemes across numerous types of hearing aids, the primary goal of these schemes is to improve the signal-to-noise ratio (SNR) by reducing the gain in the frequency region of the interfering noise source, especially when environmental noise and speech signal differed spectrally. It has been reported that many DNR algorithms only reduce the gain of the signal when noise is present, without a substantial change of the signal, in order to preserve the audibility of speech [1,2]. Some studies reported positive effects of the DNR algorithm in HAs on speech perception in background noise [3] and perceived signal quality [4,5]. However, some studies have shown no effect or even adverse effects on speech perception of the DNR algorithm. Gustafson, et al. [6] and Brons, et al. [7] found that DNR did not improve speech recognition; however, it was associated with an increase in the acceptable noise level (improved tolerance of noise). Desjardins and Doherty [8], Arehart, et al. [9], and Croghan, et al. [10] agreed that the DNR algorithm decreased the listening effort of HA users in difficult listening conditions; however, there was no improvement in speech recognition in noise. Jamieson, et al. [11] also observed no improvement in speech recognition and found an increase in errors in consonant perception with the activation of DNR. Neher and Wagender [12] reported large individual variance on the preferred strength of DNR and concluded that this feature appeared stable, but it was difficult to predict with a single measure. These findings suggest a need for objective and subjective measures when assessing the effectiveness of the DNR algorithm.
In this study, we aimed to explore the effect of DNR on music, in addition to speech perception, using objective and subjective measures, since the enjoyment of listening to music could be substantially affected by DNR processing. Music has a broader frequency spectrum, with higher energy in the low-frequency band than speech, with musical instruments often generating lower fundamental frequencies than voice [3,13-15]. Thus, amplification using HAs may omit some low- and high-frequency bands of music, and a change in input and output dynamic range of HAs might distort music sound due to DNR [14,16,17]. However, currently no study has compared perceived quality of music, in addition to speech perception, with and without activation of DNR. Therefore, we aimed to evaluate the effect of DNR on Korean speech and music perception (objective measurement), as well as a quality rating of speech and music (subjective measurement).
Subjects and Methods
Participants
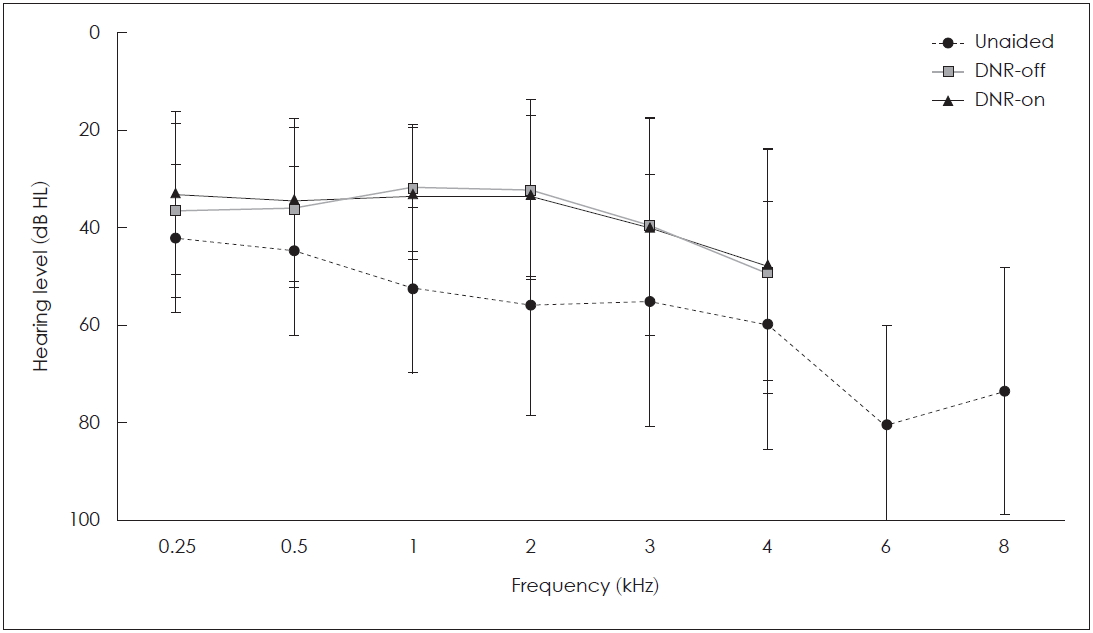
Subjects were 16 elderly HA users (3 males, 13 females), and their mean age was 58.00±10.44 years (range: 39-72 years). Participants’ unaided and aided pure tone threshold averaged across 500, 1,000, 2,000, and 3,000 Hz were 54.36±16.20 and 36.61±11.98 dB HL (DNR-on condition), respectively. Fig. 1 shows the participants’ mean hearing thresholds at frequencies ranging from 250 to 8,000 Hz in octave scales, for unaided and aided conditions, and with DNR-off and DNR-on. Table 1 shows individual demographic information, such as age, sex, unaided and aided hearing thresholds, and other HA-related features. The participants used DNR strategies in HA from 1 to 60 months. Among 16 participants, 11 subjects were unilateral HA users, and 5 were bilateral HA users. The HA of each participant was fitted based on thresholds, as well as individual preference.
As shown in Table 1, our study included three brands of hearing aids-Xino, S (Starkey, Eden Prairie, MN, USA); EY, LS (Resound, Copenhagen, Denmark); and Moxi kiss (Unitron, Switzerland). All subjects, except for the right HA of one participant, wore the receiver-in-canal HAs. Since we tested the subjects’ performance based on individual preference, we preserved the non-linear amplification features of HAs for everyday usage. Thus, the systems for compression and feedback control were switched on for all participants. As presented in Table 1, the participants’ compression thresholds and compression ratio were similar (frequently, a compression threshold of 50 dB SPL, and compression ratio of 1.5:1-2:1).
As previously stated, this study obtained objective measurements of music perception and music quality rating. Since musical experience or an individual’s background could affect their performance, subjects’ musical appreciation and background were determined using the Korean music background questionnaire (K-MBQ) [18]. Using multiple-choices, Likert rating scales, and visual analog scales, the K-MBQ evaluates five aspects of musical background: formal musical education, self-assessed musical background, satisfaction with listening to music, self-perceived quality of music, and self-reported perception of the elements of music. Table 2 shows the results of K-MBQ for 16 participants. As presented in Table 2, 9 subjects (56.25%) of 16 had not received any formal musical training, while 7 subjects (43.75%) had received some form of formal musical training. Most participants had limited knowledge or background related to music, except for 4 subjects. The response of 11 subjects (68.75%) was that they typically listen to music less than two hours a day. Among 16 subjects, 12 subjects reported that music-related sounds were pleasant. Overall, for self-perceived quality of music and self-perception of musical elements, subjects responded that it would be difficult to identify music sounds and song lyrics, as well as difficult to distinguish different instruments in a piece of music. This study was approved by the Institutional Review Board of the Eulji Medical Center, South Korea (EMCS 2016-01-012), and all participants provided written informed consent.
Test batteries used in this study
In this study, we compared performance among an unaided condition and two aided conditions, in which the DNR setting was switched on or off. Table 3 presents the test batteries used in this study, as well as the evaluated aspects of each test battery. The current study conducted two types of objective assessments: the Korean version of the Clinical Assessment of Music Perception (K-CAMP) test and speech-in-noise recognition test. The stimuli were routed through an audiometer (Madsen Astera 2; GN Otometrics, Taastrup, Denmark) and presented by a loudspeaker located at a distance of 1 m from the study subjects, with the volume set at the individual’s most comfortable levels (MCLs), both with and without HAs. We aimed to evaluate the improvement of suprathreshold auditory performance conferred by HAs, excluding the effect of restoring audibility, so that the test signal volume was sufficient to allow participants to hear in the unaided or aided condition. We assumed that the unaided sound presented at the MCL in the sound field would roughly compensate for the increased hearing thresholds of the participants, and that this condition would mean that the output level of the test stimuli would be similar to the amplified output level conferred by HAs.
For the subjective assessments, we evaluated the quality ratings of speech and music samples. In addition, we measured subjects’ HA benefit using a self-reported questionnaire, the Korean version of the Profile of Hearing Aid Benefit (K-PHAB). The order of test batteries was randomly selected to avoid any learning effects. The order of the unaided, DNR-off, and DNR-on conditions was counterbalanced across participants, and a break was provided to each subject if needed. Test batteries in each condition took about 50 minutes.
Objective assessment
Korean version of the Clinical Assessment of Music Perception test
For the objective assessment of abilities related to music perception, the K-CAMP test [19] was used. The K-CAMP has three subtests: pitch discrimination, melody recognition, and timbre recognition. Before initiating experimental testing, listeners had a brief training session, in which they listened to several pitches, different melodies, and some musical instruments. For the pitch discrimination test, the justnoticeable-difference limen (DL) in semitones was determined for the three base frequencies (262, 330, and 391 Hz) using a two-alternative forced-choice, one-up and one-down, adaptive procedure. Here, the DL refers to the minimum size of the interval between notes to distinguish between different pitches. Participants were instructed to identify a higher pitch using two buttons on a computer screen. For the melody recognition test, five different versions of each melody were prerecorded, and one version was randomly chosen for the test time. A total percent-correct score was calculated after 36 melody presentations. In the timbre (musical instrument) recognition test, sound clips of live recordings for eight musical instruments (piano, violin, cello, acoustic guitar, trumpet, flute, clarinet, and saxophone) were used. Each musical instrument played an identical five-note sequence, and were grouped by sound sources. The sound clip of each instrument was played three times in random order, and the percent of correct answers was calculated after 24 presentations.
To implement the K-CAMP test, a custom MATLAB R2012a (MathWorks, Inc., Natick, MA, USA) program was used on a laptop computer (SENS P10, Samsung Electronics, Suwon, South Korea). During the K-CAMP test, the target music stimuli were presented at an individual’s MCL. The MCL of participants was, on average, 76.25 dB HL±5.00, 62.19 dB HL±8.94, and 63.75 dB HL±5.85 for the unaided, DNR-off and DNR-on conditions, respectively. The stimuli were delivered with a loudspeaker (BR-4700, Britz International Co. Ltd, Paju, South Korea) positioned at a distance of 1 m from the participant. No feedback was given during the K-CAMP test.
Speech perception test
For the objective speech-in-noise test, word-in-noise and sentence-in-noise recognition scores were measured in the unaided, DNR-off, and DNR-on conditions. The average rootmean-square level of words and sentences from the Korean Speech Audiometry [20,21] were equated using Adobe Audition (version 3.0; Adobe Systems Inc., San Jose, CA, USA). The words and sentences were presented at the individual’s MCL, and the level of background babble noise was 6 dB less than the target speech. Thus, the word and sentence recognition scores in unaided and aided conditions (either NR-off or NR-on) were obtained at 6 dB SNR, since this SNR is one of the daily listening situations that hearing-impaired listeners often encounter [22].
Subjective assessment
Speech and music quality
We evaluated perceived quality of speech and music with materials used in a previous study [23]. All the target samples of speech and music were presented at the individual’s MCL. For the quality rating of speech, participants listened to 10 different sentences at 6 dB SNR, and they rated speech quality based on four aspects: overall impression, pleasantness, intelligibility, and loudness. The highest rating (10 points) represents the maximum rating for the aspects of overall impression, pleasantness, intelligibility. Regarding the aspect of loudness, 10 points were considered the maximum rating since the options ranged from “not loud at all” (0) to “very loud” (10).
Two different music samples were presented at 6 dB SNR for the assessment of quality rating of music. The first sample was the one-minute segment of an instrumental piece by Mozart, Serenade no. 13 in G Major (Menuetto: Allegro). The second sample was the one-minute segment of a vocal piece by Virginia Rodriguez, “Adeus Batucada,” in which the vocal piece was sung in Portuguese to avoid possible effects of lyric comprehension on the music quality. For the quality rating of music, participants were required to listen to music for 30 seconds. After listening, the participants were required to rate the music quality in the eight dimensions of music (loudness, sharpness, fullness, pleasantness, overall impression, clarity, naturalness, and echo) using a rating scale of 1 to 10.
Korean version of Profile of HA Benefit
The K-PHAB is a questionnaire that evaluates the benefits of HAs, compares the gains before and after wearing a HA, and compares the gain of HAs based on other situations. The contents of the questionnaire include the ability to communicate in a relatively easy listening situation (ease of communication, EC), the ability to communicate with multiple speakers or in noisy environments (background noise, BN), the ability to communicate in reverberant environments (reverberation, RV), the response to large or sharp environmental sounds (aversiveness of sounds, AV), and the directional recognition of speech and environmental sounds (localization, LC). Participants rated the HA benefit based on their daily life experiences. The answers were divided into seven groups, in which a score of 1 indicated “always (99%),” 2 for “most (87%),” 3 for “sometimes (75%),” 4 for “normal (50%),” 5 for “sometimes it is not (25%),” 6 for “most likely not (12%),” and 7 for “absolutely not (1%).”
Data analyses
Statistical analysis was performed using SPSS 18.0 (SPSS Inc., Chicago, IL, USA). The repeated one-way ANOVA tests were conducted to compare the mean scores among the unaided, DNR-off, and DNR-on conditions. The paired comparison tests with Bonferroni correction were also conducted when necessary. Correlation analyses were conducted to examine relations between objective and subjective measures. A significance level of 0.05 was adopted.
Results
Korean version of the Clinical Assessment of Music Perception test
Pitch discrimination
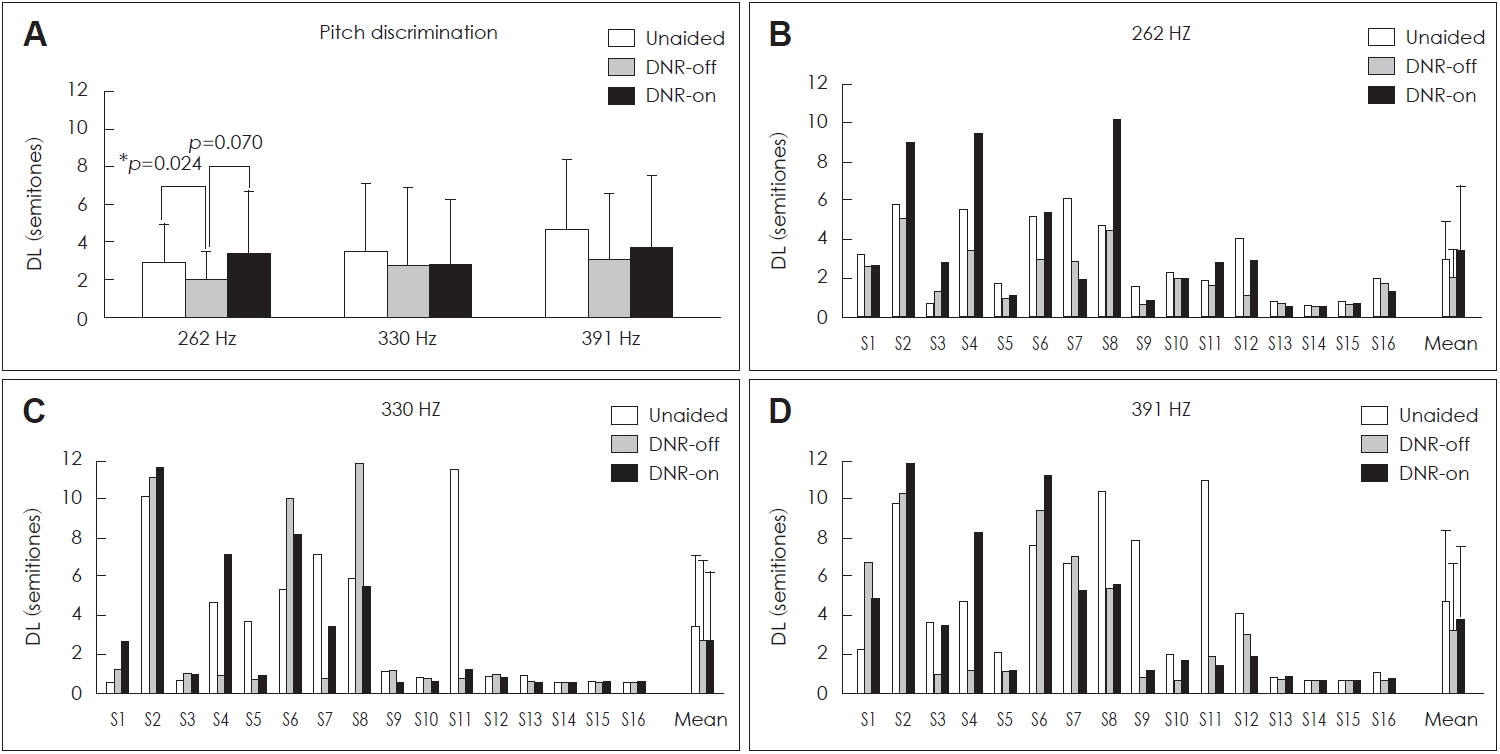
For the pitch discrimination test, the DL was examined for the base frequencies of 262, 330, and 391 Hz. As shown in Fig. 2A, for the base frequency of 262 Hz, the mean DL was 2.93±2.01, 2.05±1.41, and 3.41±3.32 for the unaided, DNR-off, and DNR-on conditions, respectively. For 330 Hz, the mean DL was 3.49±3.65, 2.79±4.10, and 2.81±3.47 for the unaided, DNR-off and DNR-on conditions, respectively. For 391 Hz, the mean DL was 4.67±3.69, 3.15±3.44, and 3.77±3.79 for the unaided, DNR-off, and DNR-on conditions, respectively. For the frequencies of 330 Hz and 391 Hz, there was no significant difference in pitch discrimination ability among the three conditions. For 262 Hz, the pitch discrimination in the DNR-off condition was better (decreased DL) than in the unaided condition (p=0.024), and an improved trend toward significance was noted than in the DNR-on condition (p=0.070); however, the unaided condition and the DNR-on conditions did not differ. Fig. 2B-D shows individual data of the pitch discrimination test. As displayed, three subjects (S2, S4, and S8) showed considerably higher DLs (poor pitch discriminations) for 262 Hz with the DNR-on condition than with the DNR-off condition.
Melody identification
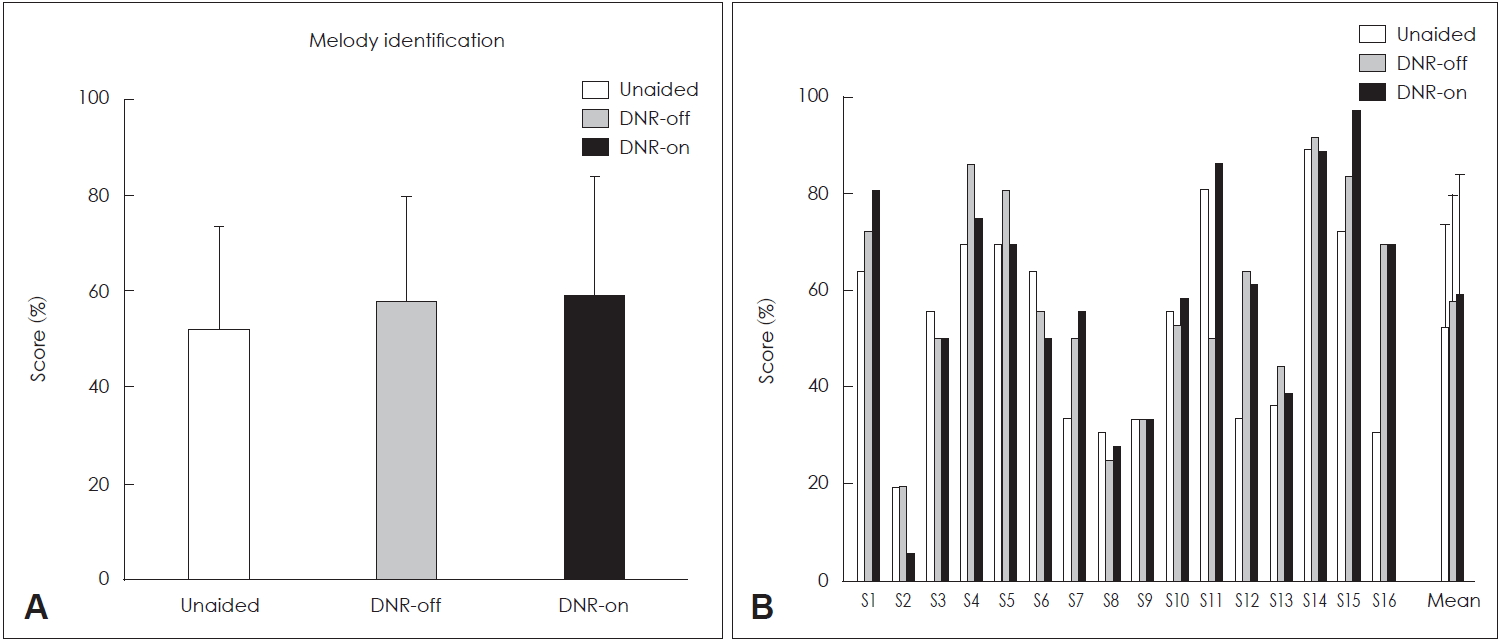
As displayed in Fig. 3A, the mean percent-correct score of the melody identification test was 52.26%±21.26, 57.99%±21.66, and 59.20%±for the unaided, DNR-off and DNR-on conditions, respectively. The melody identification scores did not differ significantly based on the DNR condition. The individual data of the melody identification test revealed that only one subject (S11) showed a remarkably better score with the DNR-on condition than with the DNR-off condition (Fig. 3B).
Timbre identification
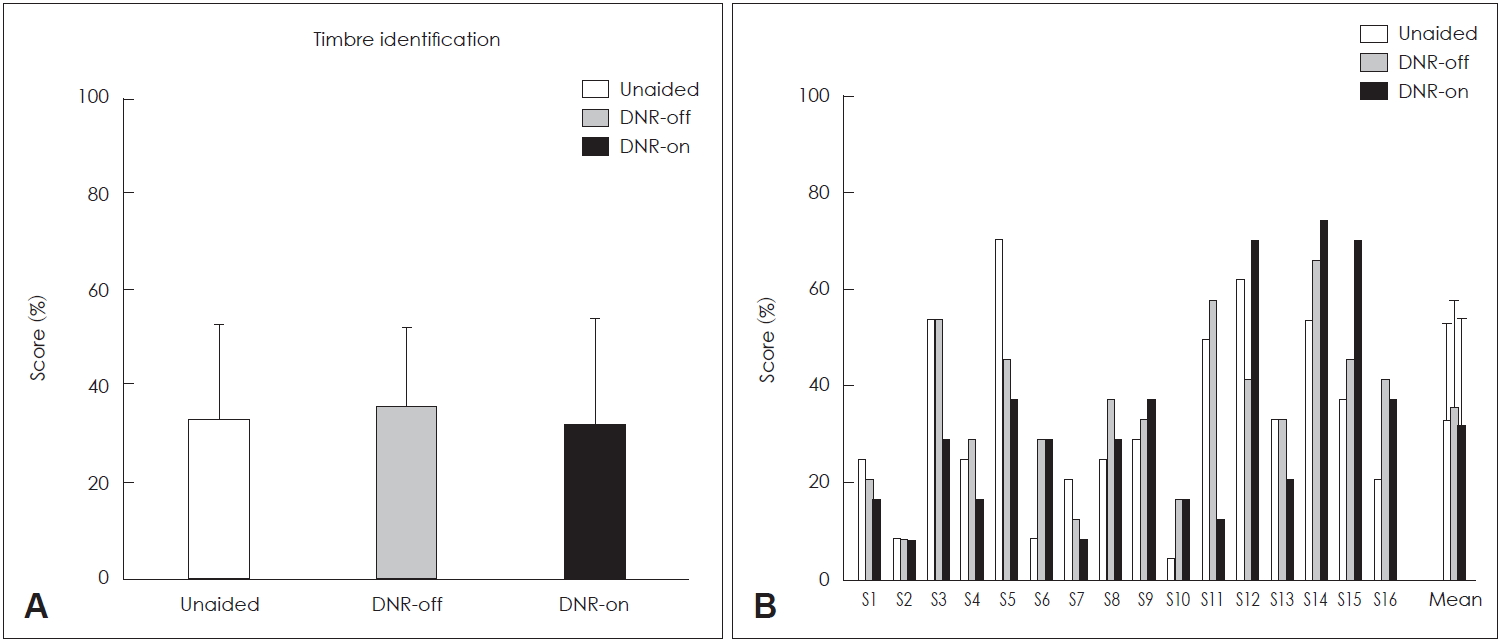
Compared to melody identification, performance for timbre identification was relatively poorer. As shown in Fig. 4A, the mean score of timbre identification was 33.07%±20.10, 32.29%±22.07, and 35.94%±16.45 for the unaided, DNR-off, and DNR-on conditions, respectively. Statistically, the score for timbre identification did not significantly differ among the three conditions. As presented in the individual data in Fig. 4A, two subjects (S12 and S15) achieved markedly higher scores with the DNR-on condition than with the DNR-off condition, whereas two subjects (S3 and S11) achieved markedly lower scores with the DNR-on condition than with the DNR-off condition (Fig. 4B).
Speech perception test
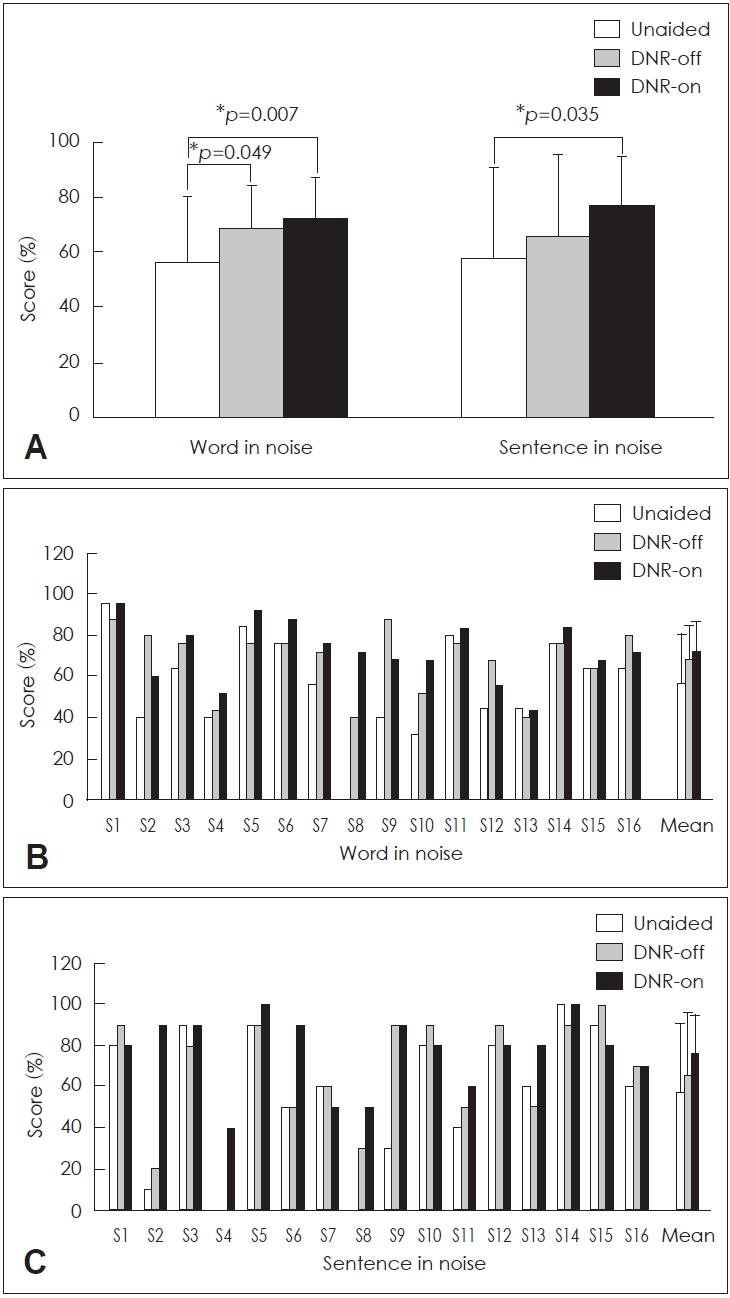
Fig. 5A shows the mean scores of word-in-noise and sentence-in-noise recognition obtained at 6 dB SNR. The mean word-recognition score was 56.25%±24.11, 68.50 %±15.99, 72.50 %±14.67 for the unaided, DNR-off, and DNR-on conditions, respectively. The mean sentence-recognition score was 57.50 %±33.17, 65.63 %±29.88, 76.88%±18.15 for the unaided, DNR-off, and DNR-on conditions, respectively. The statistical results revealed that the word recognition score in the two aided conditions (DNR-on and DNR-off) was significantly better than that in the unaided condition (p=0.007 and p=0.049, respectively). The sentence recognition score showed significantly better performance in the DNR-on condition than in the unaided condition (p=0.035). However, neither word recognition score nor sentence recognition score differed between the DNR-off and DNR-on conditions (p>0.05). Fig. 5B, C shows the individual scores when the words or sentences were presented at 6 dB SNR. Particularly in the sentence-in-noise recognition assessment, only few subjects (S2, S4, S6, S8, and S13) achieved improvement in the DNR-on condition than in the DNR-off condition.
Speech and music quality
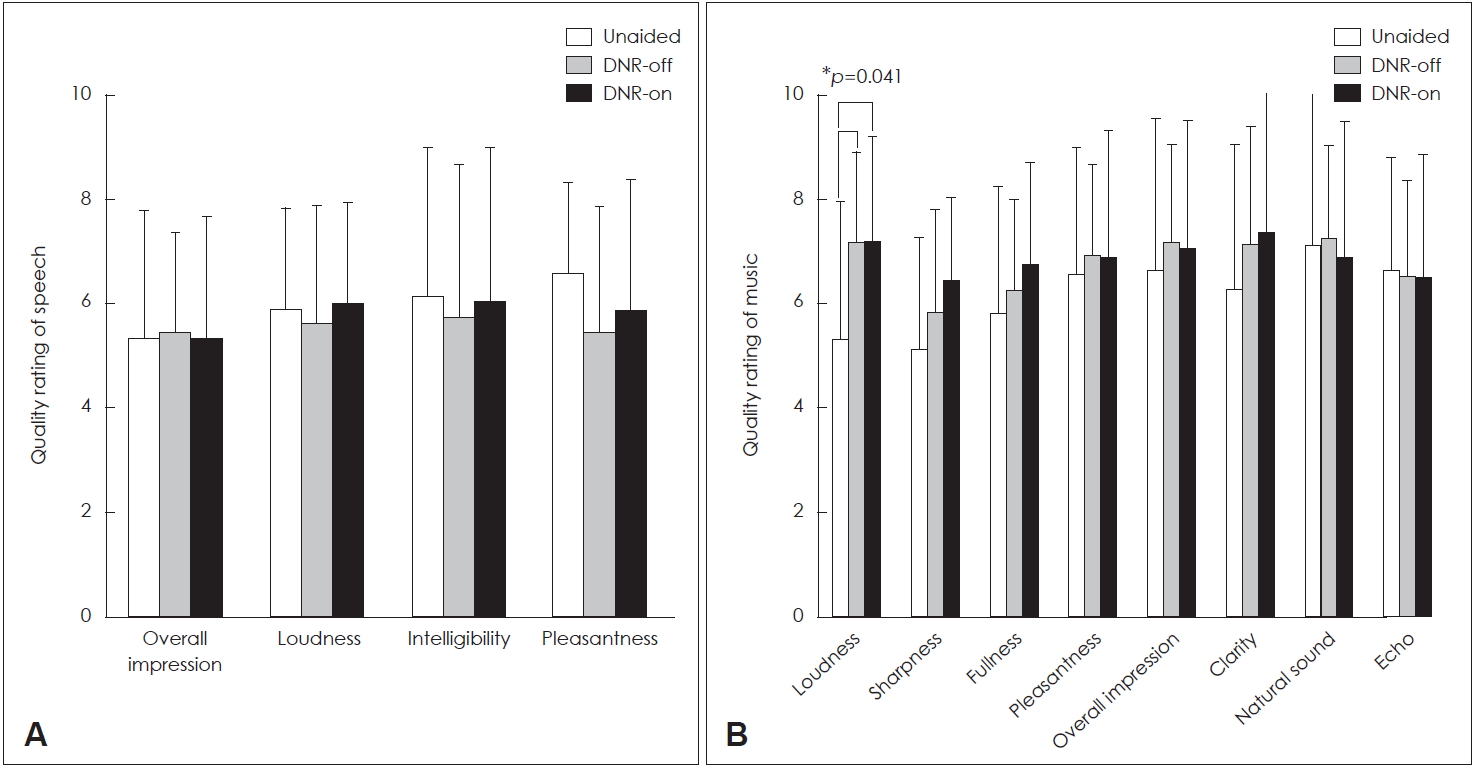
Fig. 6 displays the mean scores of the quality rating for each aspect of the questionnaire when speech (Fig. 6A) and music (Fig. 6B) are presented in the unaided, DNR-off, and DNR-on conditions. The overall mean rating of speech quality in the unaided condition was 5.31±2.47, 5.88±1.96, 6.13±2.87, and 6.56±1.75 for the aspects of impression, pleasantness, intelligibility, and loudness, respectively. For the DNR-off condition, the overall mean rating of speech quality was 5.44±1.90, 5.63±2.25, 5.75±2.91, and 5.44±2.42 for the aspects of impression, pleasantness, intelligibility, and loudness, respectively. For the DNR-on condition, the overall mean rating of speech quality was 5.30±2.36, 6.00±1.93, 6.06±2.93, and 5.88±2.50 for impression, pleasantness, intelligibility, and loudness, respectively. Statistical results revealed no significant difference in the three conditions for the rating of speech quality.
The mean quality rating of music in the unaided condition was 5.31±2.65, 5.13±2.16, 5.81±2.43, 6.56±2.42, 6.63±2.94, 6.25±2.82, 7.13±2.92, and 6.63±2.19 for the eight aspects, namely loudness, sharpness, fullness, pleasantness, overall impression, clarity, natural sound, and echo, respectively. For the DNR-off condition, the mean quality rating of music was 7.19±1.72, 5.81±1.97, 6.25±1.77, 6.94±1.73, 7.19±1.83, 7.13±2.28, 7.25±1.77, and 6.50±1.86 for the eight aspects, specifically loudness, sharpness, fullness, pleasantness, overall impression, clarity, natural sound, and echo, respectively. For the DNR-on condition, the mean quality rating of music was 7.20±2.01, 6.44±1.59, 6.75±1.95, 6.88±2.45, 7.06±2.83, 7.38±2.83, 6.88±2.63, and 6.50±2.37 for loudness, sharpness, fullness, pleasantness, overall impression, clarity, natural sound, and echo, respectively. There were no significant effects of the condition on the perceived music quality in all aspects, except loudness. For the rating of loudness, subjects felt that they were louder in the two aided conditions (DNR-on and DNR-off) than in the unaided condition (p=0.041 and p=0.005, respectively).
Korean version of Profile of HA Benefit
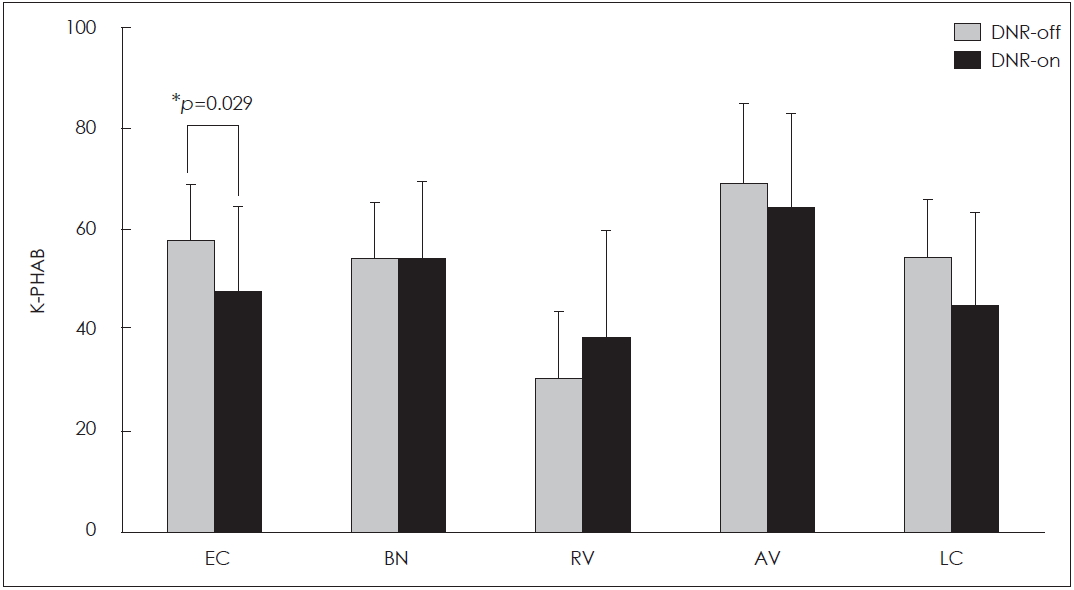
Using the K-PHAB questionnaire, the self-reported HA benefit was measured with and without the DNR algorithm for the five aspects (EC, BN, RV, AV, and LC). Fig. 7 presents the mean score of the K-PHAB questionnaire on each of the five aspects. In the DNR-off condition, the mean score of KPHAB was 57.80±10.98, 54.40±10.88, 30.40±13.27, 69±15.89, and 54.4±11.73 for EC, BN, RV, AV, and LC, respectively. In the DNR-on condition, the mean score was 47.90±16.66, 54.40±15.27, 38.50±21.40, 64.20±18.70, and 45.00±18.44 for EC, BN, RV, AV, and LC, respectively. Responses for ease of communication were better in the DNRon condition than in the DNR-off condition (p=0.029). Responses on other aspects in the K-PHAB did not differ between the DNR-on and DNR–off conditions (p>0.05).
Discussion
Background noise is known to make speech intelligibility difficult. To reduce the negative effects of background noise on speech intelligibility and sound quality, the DNR algorithm has been used in most HAs. Theoretically, the DNR algorithm provides no change in the audibility of speech; however, it reduces the gain of the signal where only noise is present [1]. DNR might reduce the annoyance of noise and decrease listening efforts, thereby reserving cognitive resources of HA users. However, most studies have found no beneficial effects of the DNR algorithm in speech recognition [6-10]. In the current study, the results of speech perception in terms of DNR were in agreement with the results of previous studies. Not surprisingly, speech intelligibility was improved by HA independent of whether the DNR was switched on or off. However, there was no evidence of a greater improvement in the performance of HA users with DNR algorithm than performance without the DNR algorithm. In the current study, subjective questionnaires revealed that DNR had a positive effect on subjective listening comfort (ease of communication), but not on the sound quality in K-PHAB. These results are in line with previous studies [8,11]. Bentler, et al. [24] compared the effect of the DNR schemes using a current commercial HA in a double-blinded design. Results showed that subjective listening comfort was better in the DNR-on condition than with DNR-off condition. However, the DNR did not improve speech perception, regardless of the visual cues.
Our objective and subjective measures revealed no benefit of the DNR algorithm on music perception. Indeed, the benefit on music perception conferred by HA is dubious, regardless of the DNR algorithm. When using HA in either the DNR-off or DNR-on condition, listeners responded that they could hear better compared to the unaided condition; however, this benefit might be due to the increase in sound volume of music or due to the use of headphones. Results of the K-CAMP test suggest that the DNR-off condition would be more beneficial for specific pitch discrimination than the DNR-on condition. Considering that the benefit of DNR would be limited when both the signal and noise were spectrally and temporally overlapped [2,25,26], the type of stimulus and background noise could substantially affect the results. This study presented 8-talker babble noises as background noise. Since our target stimuli of speech were dynamically varied in terms of spectral and temporal features, this could result in no improvement of DNR and a large individual variability in performance. Thus, future studies need to focus on the effects of DNR when spectral and temporal characteristics of background noise substantially differ from the target sound.
One of the limitations of this study was the use of HAs from three different manufacturers, and data of unilateral HA users and bilateral HA users were mixed. Indeed, each device may have inherently different sound characteristics and may use different engineering technology. Given that the DNR algorithms from different manufacturers were implemented differently among HAs [7], a further study need to conduct the acoustic analyses of the HA output and to quantify the SNR changes with or without the DNR activation.
In conclusion, overall, there were no positive effects of DNR on the speech and music perception as well as sound quality. The DNR-off condition in HAs may be beneficial for pitch discrimination at some frequencies. However, DNR positively influenced the listener’s subjective listening comfort. Given these mixed results, clinicians should be cautious when counseling patients regarding HA benefit, specifically regarding the condition of listening to music.