Introduction
In general, speech perception is assessed clinically through two methods. One method is to measure a listener's correct percentage percentage of a listener's correct response by offering speech materials under various conditions such as noise [1], reverberation [2], time alteration [3], and frequency filtering [4]. The other method of assessment is to estimate incorrect answers or errors of speech perception and to analyze their patterns [5]. When conducted with monosyllabic words, for example, the error patterns of hearing aid (HA) and cochlear implant (CI) users were examined under quiet [6] and noise conditions [7]. The researchers found that the error patterns of substitution and no response showed much higher numbers than the other patterns, thus suggesting that auditory training could be applied to reduce the highest number of errors first of all-at first. In other words, to find the most common error pattern in which hearing-impaired listeners had trouble and to reduce it with the highest priority might give us valid data for creating an effective approach to auditory training. However, little attention has been paid to a practical link between error patterns and auditory training. Furthermore, we need to study more detailed information about the error pattern of the hearing-impaired listeners who wear the HA and CI as analyzing a specific subcategory of the highest error pattern in order to devise a plan for efficient auditory training. To foster this goal, the purpose of the present study was to analyze the error patterns of phonemes for hearing-impaired listeners in quiet and noisy conditions and to gauge the phoneme having high errors, which should be an initial step to apply in auditory training, resulting in improvement of the speech perception ability of impaired listeners.
Subjects and Methods
Subjects
Thirty-four hearing-impaired listeners participated in this study: 20 HA and 14 CI users. The mean age in the HA and CI groups was 52.5 years [standard deviation (SD): 14.90] and 44.5 years (SD: 15.46), respectively. Etiologies of the individual subjects varied, but they all had symmetrical bilateral sensorineural hearing loss. The duration of auditory deprivation was 13.32 years (SD: 11.64) in the HA group and 17.77 years (SD: 13.87) in the CI group. Experience with HA and CI was 5.19 years (SD: 5.07) and 2.51 years (SD: 0.36), respectively, in those groups. Seventeen out of 20 HA users and three CI users were wearing the device bilaterally.
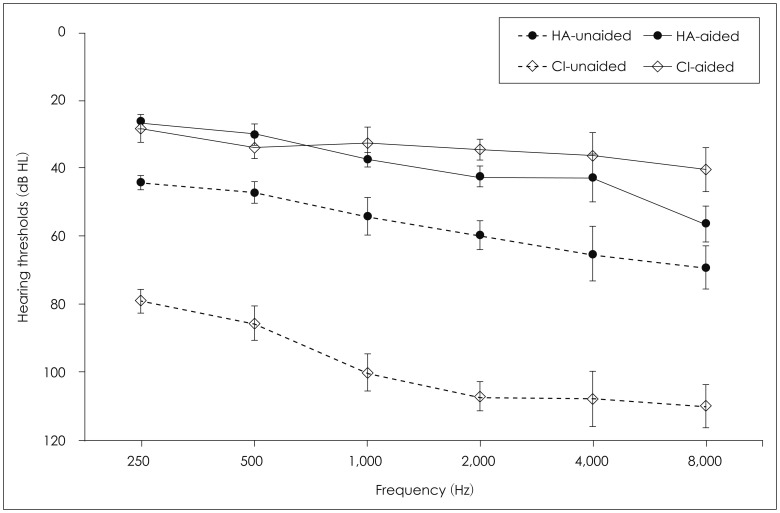
Fig. 1 indicates the unaided and aided hearing thresholds of HA and CI groups in terms of the better ear, although they had symmetrical bilateral hearing loss. There was a significant difference in the unaided threshold in all frequencies between the two groups. However, in the aided threshold, the CI group showed slightly better detection in high frequency regions than the HA group, as expected. However, the most comfortable levels (MCL) of the two groups showed little difference bilaterally, indicating 58.5┬▒3.67 dB HL and 57.14┬▒2.26 dB HL for HA and CI, respectively, in the aided condition. All subjects were native Korean speakers and all completed the informed consent form before the experiment.
Test procedure
Before initiating the experiment, all participants were checked for normal middle-ear status in an otoscopy examination and were confirmed to have a type-A tympanogram (Madsen Zordiac 901; GN Otometrics, Taastrup, Denmark). They were also tested for pure-tone audiometry by air and bone conductions from 250 to 8,000 Hz (TympStar v2; Grason-Stadler, Eden Prairie, MN, USA) using a headphone (TDH 39; Telephonics Co., Farmingdale, NY, USA) for the unaided condition and a speaker for the aided condition. As stimuli, the Korean monosyllabic test [8] consisted of 50 words per list and was produced by one male speaker recorded on a compact disc speaking on a compact disc player (4 lists├Ś50 words=total 200 words). The stimuli were presented binaurally in quiet and at two different signal-to-noise ratios (SNRs), i.e., +6, 0 dB with white noise through the speaker (0┬░ degree, 1 meter) in a sound isolation chamber. The presentation level of the monosyllables was initially set to each subject's MCL and then adjusted so that the syllables were equally loud independent of SNRs. For an easy listening condition, the quiet condition was tested first and then +6, 0 dB SNRs followed. Among four lists of the monosyllable test, three lists (e.g., one list per listening condition) were randomly selected and tested across the subjects. When the subject listened to each monosyllable, he/she produced it with accuracy. Based on recording responses of the participant, two testers wrote down the errors in accuracy if the participants responded incorrectly, and they determined the errors as a final answer after discussing discrepancy in testers' opinions.
Data analysis
First, the error scores of both groups were calculated as a function of noise level. That is, the total number of errors for each condition was counted by one subject and was classified into seven error patterns: substitution, addition, omission, substitution plus omission, substitution plus addition, fail, and no response. Second, among seven error patterns, a substitution that was the most dominant error pattern was recalculated to be maximized as a percentage at each condition. Finally, the substitution pattern was analyzed and classified into the manner of articulation such as nasal, affricative, fricative, liquid, and plosive based on a suggestion in a study by Healy, et al. [9].
Results
As expected, the total number of errors per subject gradually increased from 13.2 to 37 for the HA group and from 21.5 to 40.36 for the CI group as noise increased (Table 1). The HA users had a lower total error number than the CI users. Most error patterns of the two groups showed higher error numbers at the higher noise levels, except for the omission pattern of the CI group and a pattern of the substitution plus omission in the HA group. The error number of addition pattern did not change much in the HA group, whereas that of the CI group was the lowest in 0 dB SNR. The error number of the no response pattern increased dramatically for both HA and CI groups as noise increased. Remarkably, the substitution error pattern had the highest number in the six error patterns for both HA and CI users regardless of background conditions, indicating that substitution was the most robust error of the Korean hearing-impaired listeners (see the results of substitution in Table 1).
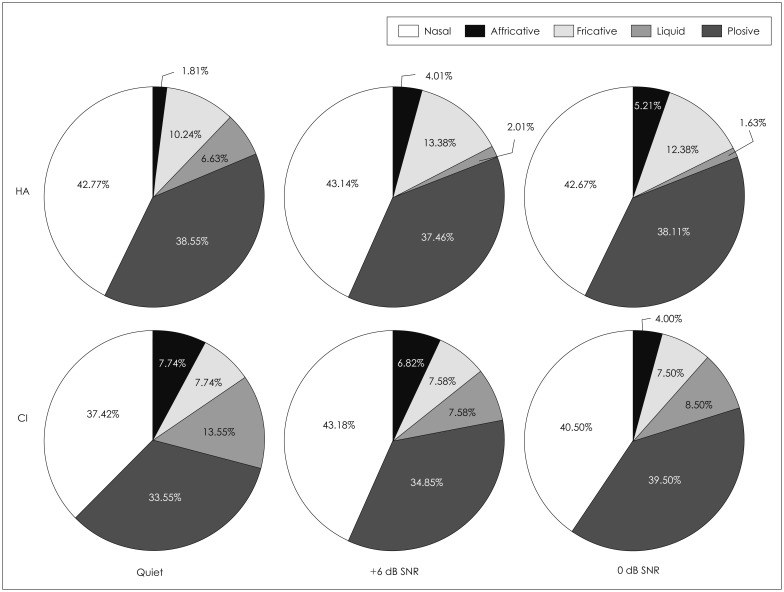
The substitution patterns of phoneme error for HA and CI groups in quiet, +6, and 0 dB SNR are classified by five types in the manner of articulation. The pie graphs of Fig. 2 used the error number of the substitution pattern in Table 1 to be maximized as a percentage. Each value in the pie graphs represents the substitution error percentage for a specific type. For example, the HA group had approximately 43% error of nasal substitution in all three conditions, while plosive and fricatives substitution patterns followed as 38.55% and 10.24% for quiet, 37.46%, and 13.38% for +6 dB SNR, and 38.11% and 12.38% for 0 dB SNR, respectively. The nasal substitution of the CI group also stood out conspicuously, having 37.42%, 43.18%, and 41% error for each condition. Similar to the HA group, the CI group also showed plosive and fricative substitution patterns as the following pattern. This explained that the most dominant error patterns of substitution were nasal and plosives in both groups. When the nasal and plosive substitution errors were added, the HA and CI groups showed them as high as 81.32% and 70.97%, 80.6% and 78.03%, and 80.78% and 80.00%, respectively, for quiet, +6, 0 dB SNR.
Discussion
The present study was designed to analyze patterns of the phoneme error in HA and CI users under quiet and noise conditions. Regardless of the noise levels, the substitution pattern showed the highest error and the nasal and plosive substitutions were remarkable in the error patterns of those users. These results should explain why there is a large substitution pattern in the hearing-impaired listeners. Ching, et al. [10] argued that after wearing the assistive listening devices, the hearing-impaired listeners are able to hear speech that they would otherwise miss hear or not hear at all. However, the impaired listeners often perceive that speech incorrectly and in a different manner to normal-hearing listeners because of speech distortion caused by amplification and noise. This distortion might differ based on degree of hearing loss and period of auditory deprivation [11], yet consequently result in specific confusions or substitution errors by the HA and CI users as their characteristics [121314] although substitution pattern of phoneme errors is changed to a fail pattern or no response pattern under a great amount of background noise [7] and there is a large individual variance [6]. Regardless, this pattern of hearing-impaired listeners was supported by our results in that the combination of nasal and plosive substitutions seemed to be consistent in either quiet or noise conditions.
According to results from Healy, et al, [9] the hearing-impaired listeners gained large benefits in the manner of articulation whereas listeners with normal hearing generally experienced the greatest gains in terms of the place of articulation. In particular, Korean nasals /n, m, ┼ŗ/, which are formed by blocking the oral passage and allowing the air to escape freely through the nose, have common acoustic features, namely ŌĆ£nasal formantŌĆØ and ŌĆ£anti-formantŌĆØ [15]. The nasal formant or so-called nasal murmur has a high intensity and low first formant at 250-300 Hz. Thus, the nasals have limitations in helping hearing-impaired listeners perceive speech and can create confusion with other sounds [9] even though the murmur provides important information for the perception as transition cues. The anti-formant property of the nasals also provides much weak energy in the second and third formants of frequency range between 300 and 4,000 Hz with large bandwidth, when compared to acoustical energy of other sounds. For example, the nasal cavity has a large area and absorbs more sound in the walls of the vocal tract, resulting in increased damping and lower amplitude of spectral peak. Furthermore, to perceive a cue of the second formant transition, which is a dynamic cue and is used when changing from consonant to vowel, is very difficult for hearing-impaired listeners who lack language experience and thus cannot receive a main cue under low-redundancy speech [16]. On the other hand, it is acknowledged that there is an adverse relationship between hearing loss and plosive perception. Although burst feature is the primary acoustic feature for consonant identification, it is very sensitive in noise [17]. Thus, if a listener has hearing loss, the Korean plosives will cause great confusion to him under noisy conditions, as we confirmed in our study.
There are two limitations of the present study that warrant further research. First, we need to determine whether vowel context has any systematic effect on consonant recognition for proving our current data in terms of the robust nasal substitution. A study by Donaldson and Kreft [18] showed that consonant-recognition scores varied by 15% or more depending on following various vowels. They concluded that vowel-context effects were strongest for /d, j, n, k, m, l/ consonants, and two of them are nasal phoneme. A second issue comes from our findings, i.e., nasal or plosive substitution of speech recognition in the hearing-impaired listeners, whether speech production characteristic in hearing-impaired listeners, is nasality. Previous studies have shown that excessive nasality is often observed in the speech of hearing-impaired listeners who cannot adequately monitor this subtle characteristic of speech [19]. That is, simultaneous oral and nasal airflows were obtained from a group of moderate-to-profound hearing-impaired adults during production of the stop consonants /p, t, k, b, d, g/ [20].
Despite these limitations, the results of the current study have implications for speech amplification strategy in noise and aural rehabilitation for hearing-impaired listeners. For one possible practical application, clinicians should focus on discrimination and identification of nasal and plosive substitutions. For instance, if nasal substitution is dominant in a HA user, auditory training for reducing nasal substitutions would be an initial step for him to enhance his speech perception ability. Because this strategy is able to reduce the highest error with accuracy at the beginning of auditory training, it will provide effective training protocol for either clinicians or patients in terms of a shorter total training period and a saving of expenses.